
服务注册与发现-12、Zookeeper
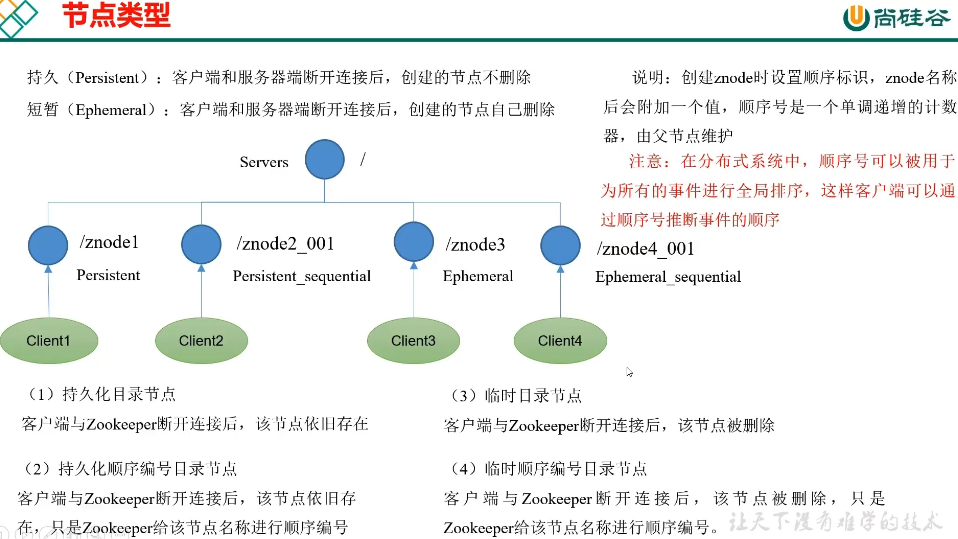
1. 节点类型
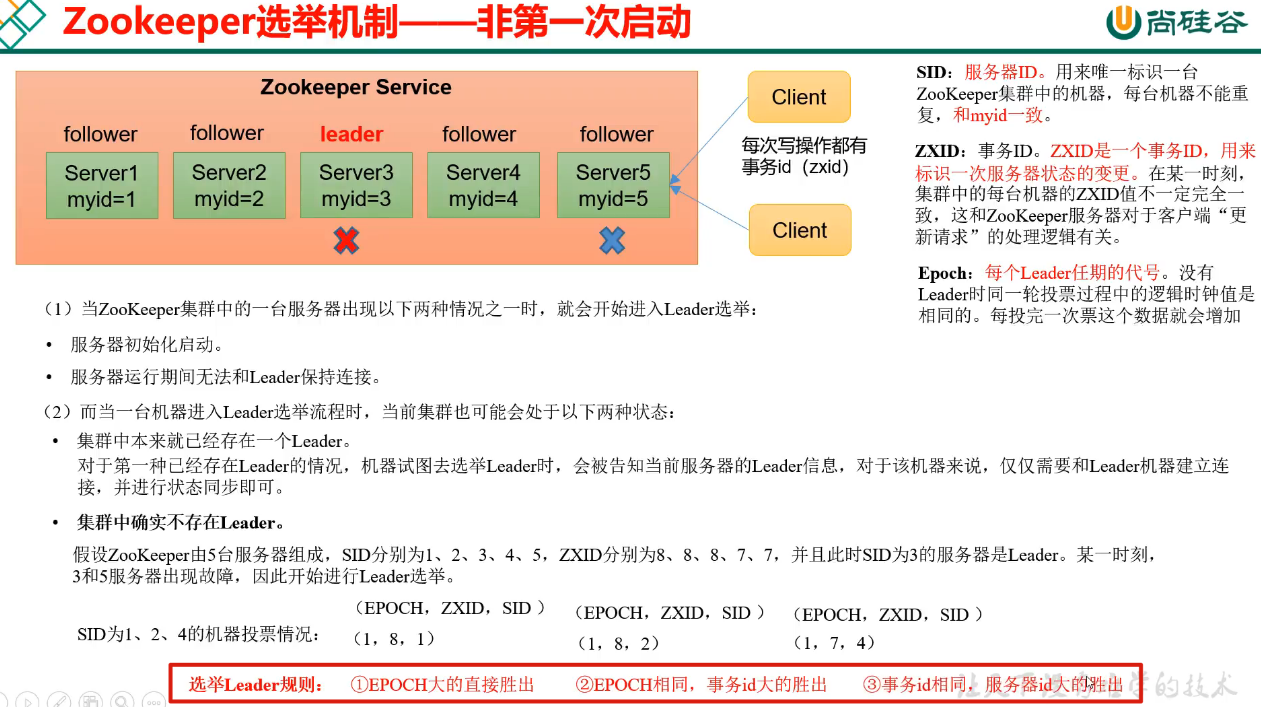
2. 选举过程
2.1. 概述

2.2. 初始化选举

2.3. 崩溃恢复
3. 写数据流程
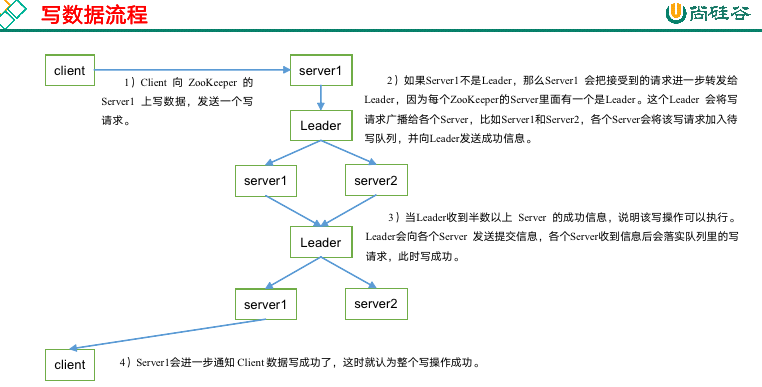
如果是请求的 leader,则最后是由 leader 通知 Client 数据写成功了。
4. 数据同步

5. 监听器原理
5.1. Watch 机制
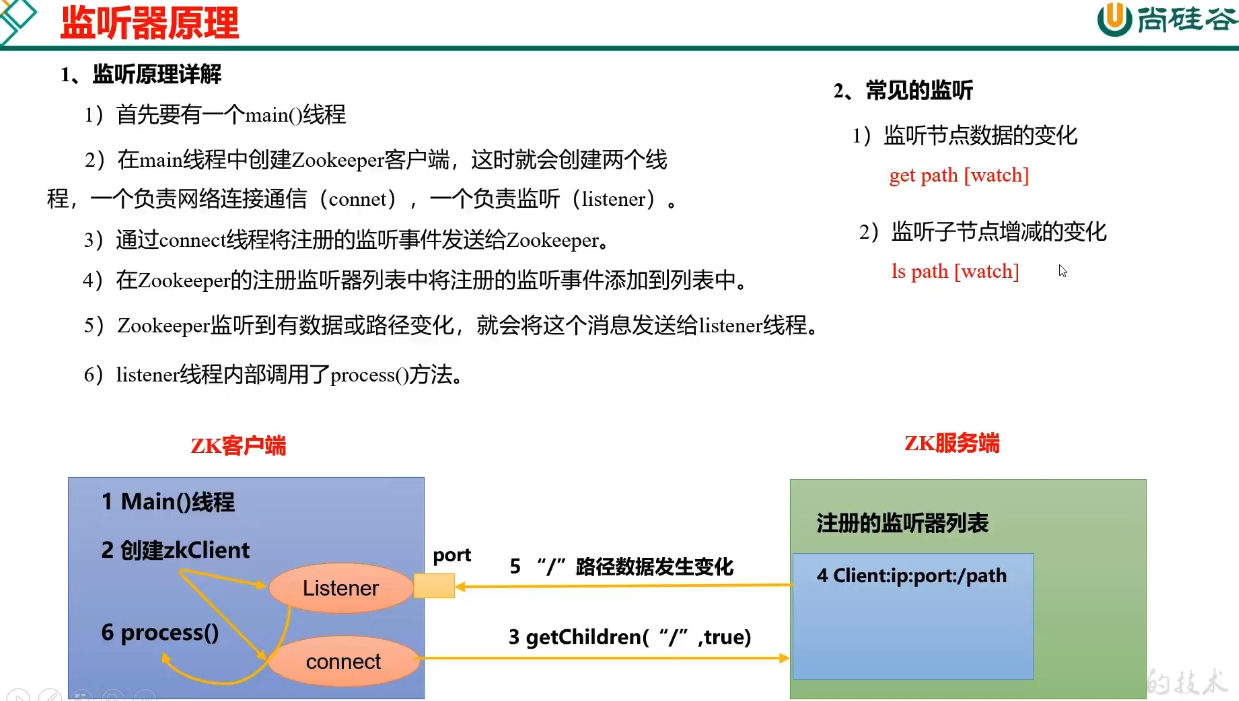
5.1.1. 详细逻辑
Zookeeper 是一个分布式协调组件,为分布式架构下的多个应用组件提供了顺序访问控制能力。它的数据存储采用了类似于文件系统的树形结构,以节点的方式来管理存储在 Zookeeper 上的数据。
Zookeeper 提供了一个 Watch 机制,可以让客户端感知到 Zookeeper Server 上存储的数据变化,这样一种机制可以让 Zookeeper 实现很多的场景,比如配置中心、注册中心等。
Watch 机制采用了 Push 的方式来实现,也就是说客户端和 Zookeeper Server 会建立一个长连接,一旦监听的指定节点发生了变化,就会通过这个长连接把变化的事件推送给客户端。
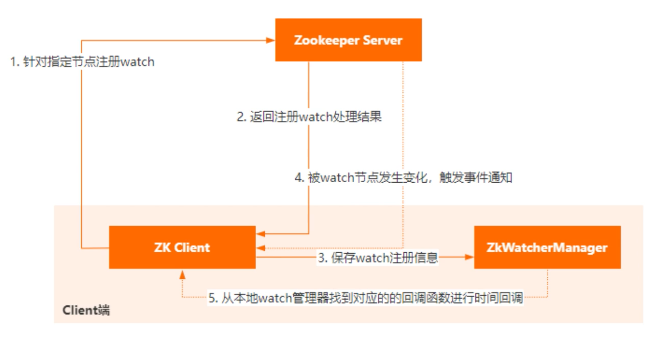
Watch 的具体流程分为几个部分:
首先,是客户端通过指定命令比如 exists、get,对特定路径增加 watch 然后服务端收到请求以后,用 HashMap 保存这个客户端会话以及对应关注的节点路径,同时客户端也会使用 HashMap 存储指定节点和事件回调函数的对应关系。
当服务端指定被 watch 的节点发生变化后,就会找到这个节点对应的会话,把变化的事件和节点信息发给这个客户端。 客户端收到请求以后,从 ZkWatcherManager 里面对应的回调方法进行调用, 完成事件变更的通知。
5.2. 存在问题

https://www.bilibili.com/video/BV1t7411j7P7?p=4

6. 面试题
6.1. 生产集群安装多少台 ZK

7. 应用场景
7.1. 集群管理 - 副本机制
在多个节点组成的集群中,为了保证集群的 HA 特性,每个节点都会冗余一份数据副本。这种情况下需要保证客户端访问集群中的任意一个节点都是最新的数据
Zookeeper 提供了 CP 的模型,来保证集群中的每个节点的数据一致性,当然 Zk 本身的集群并不是 CP 模型,而是顺序一致性模型,如果要保证 CP 特性,需要调用 sync 同步方法。
7.2. master 选举
在多个节点组成的集群中,为了降低集群数据同步的复杂度,一般会存在 Master 和 Slave 两种角色的节点,Master 负责事务和非事务请求处理,Slave 负责非事务请求处理。但是在分布式系统中如何确定某个节点是 Master 还是 Slave,也成了一个难度不小的挑战。基于这三类常见场景的需求,所以产生了 Zookeeper 这样一个中间件。它是一个分布式开源协调组件,简单来说,就是类似于一个裁判员的角色,专门负责协调和解决分布式系统中的各类问题。比如,针对上述描述的问题,Zookeeper 都可以解决。
Zookeeper 可以利用持久化节点来存储和管理其他集群节点的信息,从而进行 Master 选举机制。或者还可以利用集群中的有序节点特性,来实现 Master 选举。 目前主流的 Kafka、Hbase、Hadoop 都是通过 Zookeeper 来实现集群节点的主从选举。
总的来说,Zookeeper 就是经典的分布式数据一致性解决方案,致力于为分布式应用提供高性能、高可用,并且具有严格顺序访问控制能力的分布式协调服务。它底层通过基于 Paxos 算法演化而来的 ZAB 协议实现。
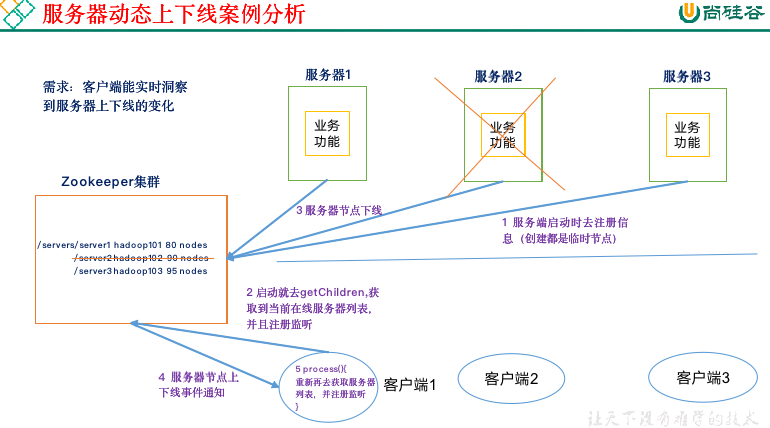
7.3. 监听服务器节点动态上下线案例⭐️🔴
先在集群上创建/servers 永久节点
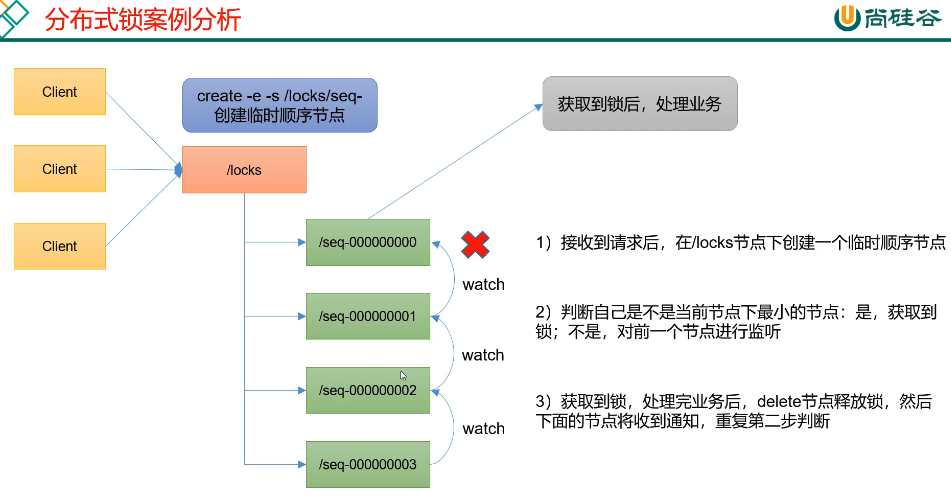
7.4. 分布式锁 - 临时顺序节点⭐️🔴
❕ ^018oy5
8. 相关算法
8.1. ZAB 协议


8.2. CAP 理论

9. 参考与感谢
9.1. 尚硅谷大数据
9.1.1. 视频
9.1.2. 资料
1 | |
尚硅谷大数据技术之Zookeeper
 微信
微信 支付宝
支付宝

