
框架源码专题-MySQL-7、索引原理
1. 什么是索引
索引(index)是帮助 MySQL 高效获取数据的数据结构(有序)。在数据之外,数据库系统还维护者满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法,这种数据结构就是索引。
1.1. 索引优势劣势
优势
1) 类似于书籍的目录索引,提高数据检索的效率,降低数据库的 IO 成本。
2) 通过索引列对数据进行排序,降低数据排序的成本,降低 CPU 的消耗。
劣势
1) 实际上索引也是一张表,该表中保存了主键与索引字段,并指向实体类的记录,所以索引列也是要占用空间的。
2) 虽然索引大大提高了查询效率,同时却也降低更新表的速度,如对表进行 INSERT、UPDATE、DELETE。因为更新表时,MySQL 不仅要保存数据,还要保存一下索引文件每次更新添加了索引列的字段,都会调整因为更新所带来的键值变化后的索引信息。
1.2. 索引结构
索引是在 MySQL 的存储引擎层中实现的,而不是在服务器层实现的。所以每种存储引擎的索引都不一定完全相同,也不是所有的存储引擎都支持所有的索引类型的。MySQL 目前提供了以下 4 种索引:
- BTREE 索引 : 最常见的索引类型,大部分索引都支持 B 树索引。
- HASH 索引:只有 Memory 引擎支持 , 使用场景简单 。
- R-tree 索引(空间索引):空间索引是 MyISAM 引擎的一个特殊索引类型,主要用于地理空间数据类型,通常使用较少,不做特别介绍。
- Full-text (全文索引) :全文索引也是 MyISAM 的一个特殊索引类型,主要用于全文索引,InnoDB 从 Mysql5.6 版本开始支持全文索引。
1.2.1. MyIsAm
叶子节点存储真实数据的磁盘地址
索引和数据分开存放
.myd 即 my data,表数据文件
.myi 即 my index,索引文件
1.2.2. InnoDB
.ibd
1.2.3. B+Tree 原理
[[数据结构-0、数据结构与算法-汇总#^uxdwyi]]
1.2.4. 查询流程
InnoDB 里的 B+ 树中的 每个节点都是一个数据页,结构示意图如下:
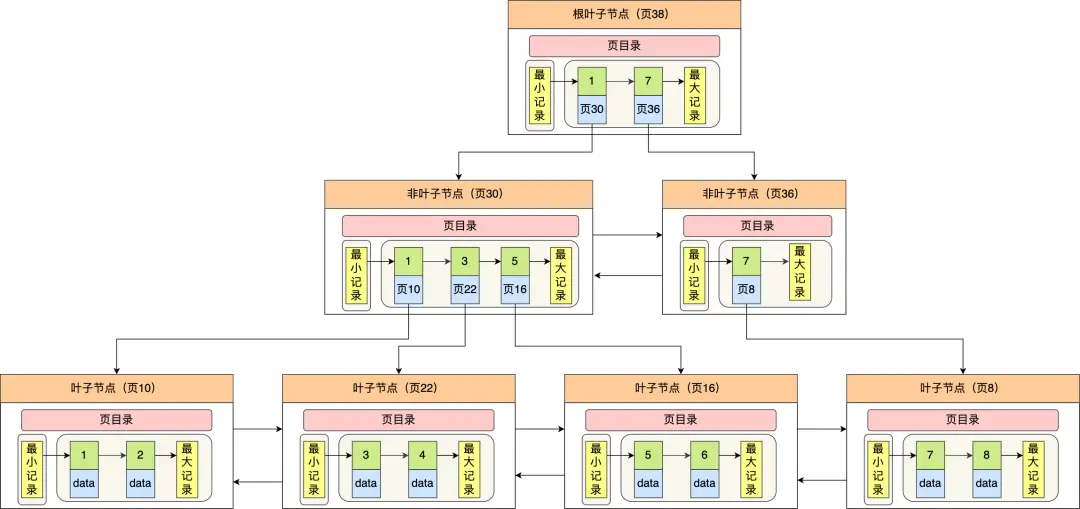
通过上图,我们看出 B+ 树的特点:
- 只有叶子节点(最底层的节点)才存放了数据,非叶子节点(其他上层节)仅用来存放目录项作为索引。
- 非叶子节点分为不同层次,通过分层来降低每一层的搜索量;
- 所有节点按照索引键大小排序,构成一个双向链表,便于范围查询;
我们再看看 B+ 树如何实现快速查找主键为 6 的记录,以上图为例子:
- 从根节点开始,通过二分法快速定位到符合页内范围包含查询值的页,因为查询的主键值为 6,在
[1, 7)范围之间,所以到页 30 中查找更详细的目录项; - 在非叶子节点(页 30)中,继续通过二分法快速定位到符合页内范围包含查询值的页,主键值大于 5,所以就到叶子节点(页 16)查找记录;
- 接着,在叶子节点(页 16)中,通过槽查找记录时,使用二分法快速定位要查询的记录在哪个槽(哪个记录分组),定位到槽后,再遍历槽内的所有记录,找到主键为 6 的记录。
可以看到,在定位记录所在哪一个页时,也是通过二分法快速定位到包含该记录的页。定位到该页后,又会在该页内进行二分法快速定位记录所在的分组(槽号),最后在分组内进行遍历查找。
1.2.5. 总结
InnoDB 的数据是按「数据页」为单位来读写的,默认数据页大小为 16 KB。每个数据页之间通过双向链表的形式组织起来,物理上不连续,但是逻辑上连续。
数据页内包含用户记录,每个记录之间用单向链表的方式组织起来,为了加快在数据页内高效查询记录,设计了一个页目录,页目录存储各个槽(分组),且主键值是有序的,于是可以通过二分查找法的方式进行检索从而提高效率。
为了高效查询记录所在的数据页,InnoDB 采用 b+ 树作为索引,每个节点都是一个数据页。
如果叶子节点存储的是实际数据的就是聚簇索引,一个表只能有一个聚簇索引;如果叶子节点存储的不是实际数据,而是主键值则就是二级索引,一个表中可以有多个二级索引。
在使用二级索引进行查找数据时,如果查询的数据能在二级索引找到,那么就是「索引覆盖」操作,如果查询的数据不在二级索引里,就需要先在二级索引找到主键值,需要去聚簇索引中获得数据行,这个过程就叫作「回表」。
2. 索引为什么这么快⭐️🔴
❕ ^gkr68m
2.1. 局部性原理和 IO
考虑到磁盘 IO 是非常高昂的操作,计算机操作系统做了一些优化,当一次 IO 时,不光把当前磁盘地址的数据,而是把相邻的数据也都读取到内存缓冲区内,因为局部预读性原理告诉我们,当计算机访问一个地址的数据的时候,与其相邻的数据也会很快被访问到。
每一次 IO 读取的数据我们称之为一页 (page)。具体一页有多大数据跟操作系统有关,一般为 16k,也就是我们读取一页内的数据时候,实际上才发生了一次 IO,这个理论对于索引的数据结构设计非常有帮助。
数据库的 I/O 操作的最小单位是页,InnoDB 数据页的默认大小是 16KB,意味着数据库每次读写都是以 16KB 为单位的,一次最少从磁盘中读取 16K 的内容到内存中,一次最少把内存中的 16K 内容刷新到磁盘中。
准确来说,只有命中了索引列的查询,才能提升效率。并且,即便是命中了索引,查询效率也不一定高,比如在性别字段上加索引。因为数据的散列度不高,导致可能会遍历整颗 B+ 树。
InnoDB 采用了 B+ 树这种多路平衡查找树来存储索引,使得在千万级数量的情况下,树的高度可以控制在 3 层以内。而层高代表磁盘 IO 的次数,因此基于索引查询减少了磁盘 IO 次数。
2.2. Page(页)
- 页是 InnoDB 磁盘管理的最小单位。
- 在 InnoDB 存储引擎中,默认每个页的大小为 16KB。
- 从 InnoDB1.2.x 版本开始,可以通过参数 innodb_page_size 将页的大小设置为 4K,8K,16K。
- InnoDB 存储引擎中,常见的页类型有:数据页,undo 页,系统页,事务数据页,插入缓冲位图页,插入缓冲空闲列表页 等。
数据页包括七个部分,结构如下图
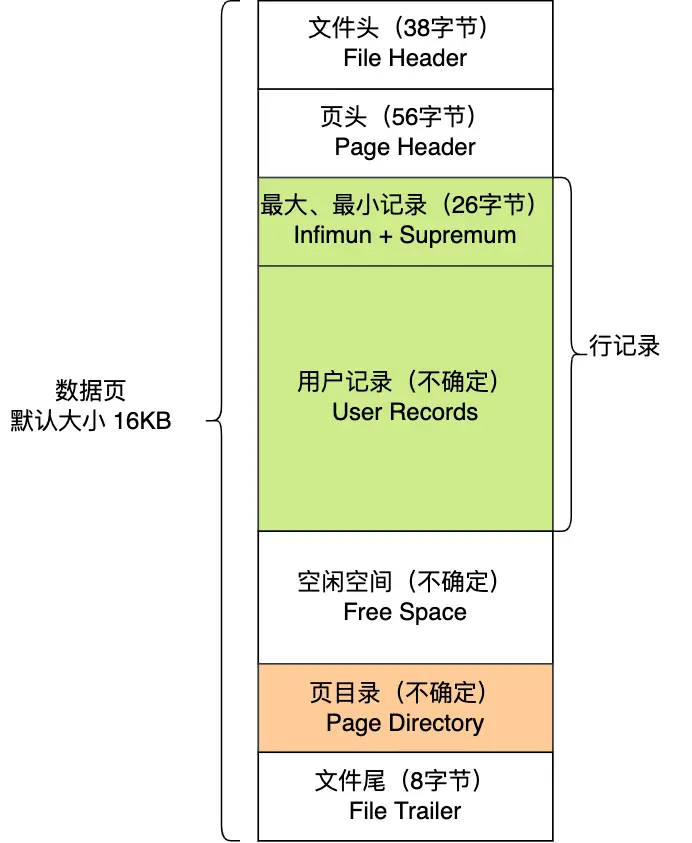
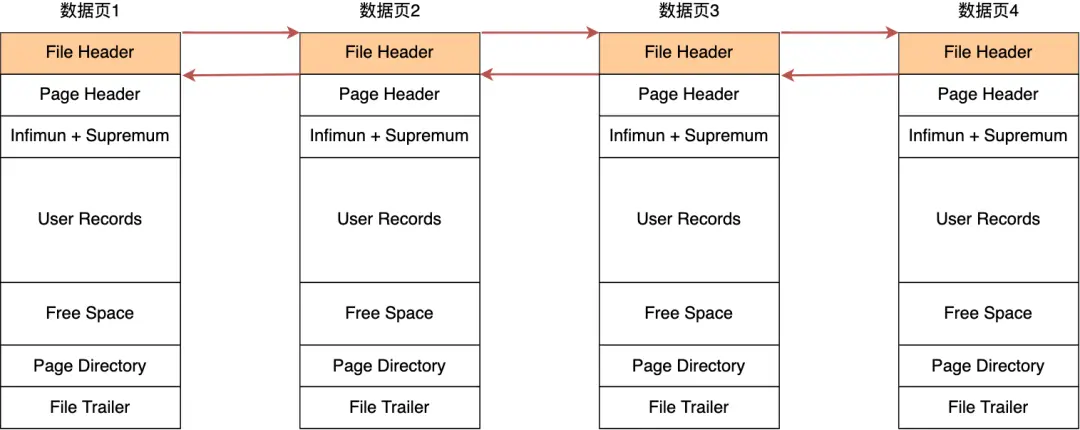
在 File Header 中有两个指针,分别指向上一个数据页和下一个数据页,连接起来的页相当于一个双向的链表,如下图所示:
2.2.1. User Records(用户记录)
数据页中的记录按照「主键」顺序组成单向链表,单向链表的特点就是插入、删除非常方便,但是检索效率不高,最差的情况下需要遍历链表上的所有节点才能完成检索。
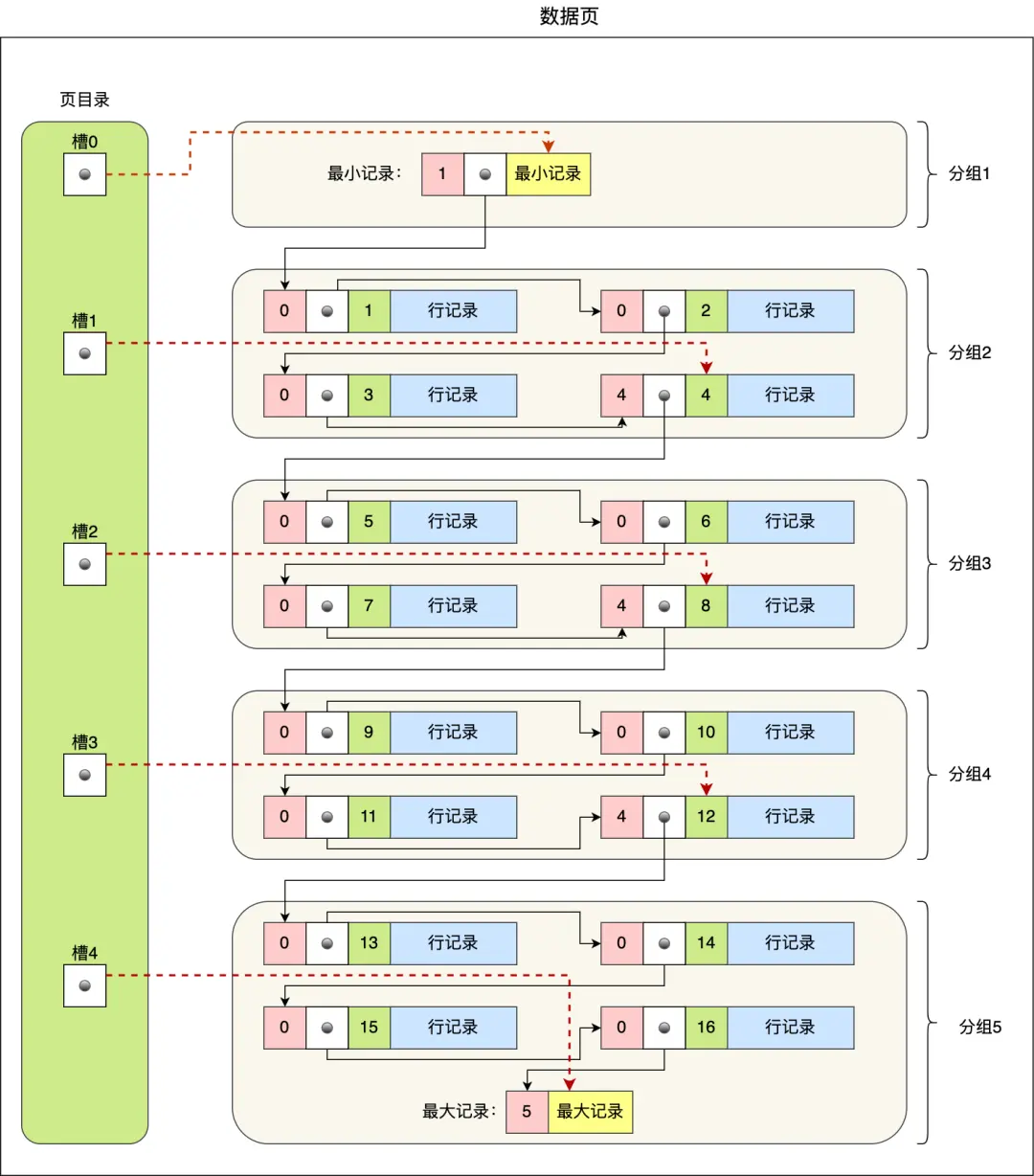
2.2.2. Page Directory(页目录)
因此,数据页中有一个 页目录,起到记录的索引作用,一个数据页中的记录检索,因为一个数据页中的记录是有限的,且主键值是有序的,所以通过对所有记录进行分组,然后将组号(槽号)存储到页目录,使其起到索引作用,通过二分查找的方法快速检索到记录在哪个分组,来降低检索的时间复杂度。
那 InnoDB 是如何给记录创建页目录的呢?页目录与记录的关系如下图:
2.3. 总结
InnoDB 的数据是按「数据页」为单位来读写的,默认数据页大小为 16 KB。每个数据页之间通过双向链表的形式组织起来,物理上不连续,但是逻辑上连续。
数据页内包含用户记录,每个记录之间用单向链表的方式组织起来,为了加快在数据页内高效查询记录,设计了一个页目录,页目录存储各个槽(分组),且主键值是有序的,于是可以通过二分查找法的方式进行检索从而提高效率。
为了高效查询记录所在的数据页,InnoDB 采用 b+ 树作为索引,每个节点都是一个数据页。
如果叶子节点存储的是实际数据的就是聚簇索引,一个表只能有一个聚簇索引;如果叶子节点存储的不是实际数据,而是主键值则就是二级索引,一个表中可以有多个二级索引。
在使用二级索引进行查找数据时,如果查询的数据能在二级索引找到,那么就是「索引覆盖」操作,如果查询的数据不在二级索引里,就需要先在二级索引找到主键值,需要去聚簇索引中获得数据行,这个过程就叫作「回表」。
https://tech.meituan.com/2014/06/30/mysql-index.html
https://juejin.im/post/5d42f48cf265da03ab422e08
https://www.bilibili.com/video/BV1p4411D7bV?p=4
3. 设计原则
3.1. 索引字段
1. 较频繁的作为查询条件的字段应该创建索引
提高数据查询检索的效率最有效的办法就是减少须要访问的数据量,从上面索引的益处中我们知道,索引正是减少通过索引键字段作为查询条件的 Query 的 IO 量之最有效手段。所以一般来说应该为较为频繁的查询条件字段创建索引。
2. 唯一性太差的字段不适合单独创建索引,即使频繁作为查询条件
唯一性太差的字段主要是指哪些呢?如状态字段、类型字段等这些字段中存放的数据可能总共就是那么几个或几十个值重复使用,每个值都会存在于成千上万 或更多的记录中。对于这类字段,完全没有必要创建单独的索引。因为即使创建了索引,MySQL Query Optimizer 大多数时候也不会去选择使用,如果什么时候 MySQL Query Optimizer 选择了这种索引,那么非常遗憾地告诉你,这可能会带来极大的性能问题。由于索引字段中每个值都含有大量的记录,那么存储引擎在根据索引 访问数据的时候会带来大量的随机 IO,甚至有些时候还会出现大量的重复 IO。
3. 更新非常频繁的字段不适合创建索引
4. 不会出现在 WHERE 子句中的字段不该创建索引
5. 对于单键索引,尽量选择过滤性更好的索引(例如:手机号,邮件,身份证)
6. 组合索引,过滤性最好的字段在索引字段顺序中,位置越靠前越好
7. 选择组合索引时,尽量包含 where 中更多字段的索引
3.2. 单键索引还是组合索引
组合索引弊端:组合索引中因为有多个字段存在,理论上被更新的可能性肯定比单键索引要大很多,这样带来的附加成本也就比单键索引要高
在大概了解了 MySQL 各种类型的索引,以及索引本身的利弊与判断一个字段是否须要创建索引之后,就要着手创建索引来优化 Query 了。在很多时候,WHERE 子句中的过滤条件并不只是针对于单一的某个字段,经常会有多个字段一起作为查询过滤条件存在于 WHERE 子句中。在这种时候,就必须要判断是该仅仅为过滤性最好的字段建立索引,还是该在所有字段(过滤条件中的)上建立一个组合索引。
在一般的应用场景中,只要不是其中某个过滤字段在大多数场景下能过滤 90% 以上的数据,而其他的过滤字段会频繁的更新,一般更倾向于创建组合索引, 尤其是在并发量较高的场景下。因为当并发量较高的时候,即使只为每个 Query 节省了很少的 IO 消耗,但因为执行量非常大,所节省的资源总量仍然是非常可观的。
https://www.jb51.net/article/50703.htm
3.3. 创建索引的一些规则
1、权衡索引个数与 DML 之间关系,DML 也就是插入、删除数据操作。这里需要权衡一个问题,建立索引的目的是为了提高查询效率的,但建立的索引过多,会影响插入、删除数据的速度,因为我们修改的表数据,索引也要跟着修改。这里需要权衡我们的操作是查询多还是修改多。
2、把索引与对应的表放在不同的表空间。当读取一个表时表与索引是同时进行的。如果表与索引和在一个表空间里就会产生资源竞争,放在两个表这空就可并行执行。
3、最好使用一样大小是块。 Oracle 默认五块,读一次 I/O,如果你定义 6 个块或 10 个块都需要读取两次 I/O。最好是 5 的整数倍更能提高效率。
4、如果一个表很大,建立索引的时间很长,因为建立索引也会产生大量的 redo 信息,所以在创建索引时可以设置不产生或少产生 redo 信息。只要表数据存在,索引失败了大不了再建,所以可以不需要产生 redo 信息。
5、建索引的时候应该根据具体的业务 SQL 来创建,特别是 where 条件,还有 where 条件的顺序,尽量将过滤大范围的放在后面,因为 SQL 执行是从后往前的。
https://blog.csdn.net/zhongguoren666/article/details/6752153
1、表的主键、外键必须有索引;
2、数据量超过 300 的表应该有索引;
3、经常与其他表进行连接的表,在连接字段上应该建立索引;
4、经常出现在 Where 子句中的字段,特别是大表的字段,应该建立索引;
5、索引应该建在选择性高的字段上;
6、索引应该建在小字段上,对于大的文本字段甚至超长字段,不要建索引;
4. Oracle 索引优化
https://blog.csdn.net/runrabbit/article/details/52151990
Sql 优化:
当 Oracle 数据库拿到 SQL 语句时,其会根据查询优化器分析该语句,并根据分析结果生成查询执行计划。 也就是说,数据库是执行的查询计划,而不是 Sql 语句。 查询优化器有 rule-based-optimizer(基于规则的查询优化器) 和 Cost-Based-optimizer(基于成本的查询优化器)。 其中基于规则的查询优化器在 10g 版本中消失。 对于规则查询,其最后查询的是全表扫描。而 CBO 则会根据统计信息进行最后的选择。
1、先执行 From ->Where ->Group By->Order By
2、执行 From 字句是从右往左进行执行。因此必须选择记录条数最少的表放在右边。
3、对于 Where 字句其执行顺序是从后向前执行、因此可以过滤最大数量记录的条件必须写在 Where 子句的末尾,而对于多表之间的连接,则写在之前。 因为这样进行连接时,可以去掉大多不重复的项。
\4. SELECT 子句中避免使用 (_)ORACLE 在解析的过程中, 会将’_’ 依次转换成所有的列名, 这个工作是通过查询数据字典完成的, 这意味着将耗费更多的时间
6、用 UNION 替换 OR(适用于索引列) union: 是将两个查询的结果集进行追加在一起,它不会引起列的变化。 由于是追加操作,需要两个结果集的列数应该是相关的, 并且相应列的数据类型也应该相当的。union 返回两个结果集,同时将两个结果集重复的项进行消除。 如果不进行消除,用 UNOIN ALL.
通常情况下, 用 UNION 替换 WHERE 子句中的 OR 将会起到较好的效果. 对索引列使用 OR 将造成全表扫描. 注意, 以上规则只针对多个索引列有效. 如果有 column 没有被索引, 查询效率可能会因为你没有选择 OR 而降低. 在下面的例子中, LOC_ID 和 REGION 上都建有索引.
高效: SELECT LOC_ID , LOC_DESC , REGION FROM LOCATION WHERE LOC_ID = 10 UNION SELECT LOC_ID , LOC_DESC , REGION FROM LOCATION WHERE REGION = “MELBOURNE”
低效: SELECT LOC_ID , LOC_DESC , REGION FROM LOCATION WHERE LOC_ID = 10 OR REGION = “MELBOURNE” 如果你坚持要用 OR, 那就需要返回记录最少的索引列写在最前面.
\7. 用 EXISTS 替代 IN、用 NOT EXISTS 替代 NOT IN 在许多基于基础表的查询中, 为了满足一个条件, 往往需要对另一个表进行联接. 在这种情况下, 使用 EXISTS(或 NOT EXISTS) 通常将提高查询的效率. 在子查询中, NOT IN 子句将执行一个内部的排序和合并. 无论在哪种情况下, NOT IN 都是最低效的 (因为它对子查询中的表执行了一个全表遍历). 为了避免使用 NOT IN, 我们可以把它改写成外连接 (Outer Joins) 或 NOT EXISTS.
例子:
高效: SELECT * FROM EMP (基础表) WHERE EMPNO > 0 AND EXISTS (SELECT ‘X’ FROM DEPT WHERE DEPT.DEPTNO = EMP.DEPTNO AND LOC = ‘MELB’)
低效: SELECT * FROM EMP (基础表) WHERE EMPNO > 0 AND DEPTNO IN(SELECT DEPTNO FROM DEPT WHERE LOC = ‘MELB’)
5. 索引失效
❕ ^fey0iq
函数 - 计算 - 自动类型转换、orderby 没条件
5.1. 使用函数或计算
SELECT Col FROM tbl WHERE substr(name ,1 ,3 ) = ‘ABC’ 或者 SELECT Col FROM tbl WHERE name LIKE ‘%ABC%’ 而 SELECT Col FROM tbl WHERE name LIKE ‘ABC%’ 会使用索引。
SELECT Col FROM tbl WHERE col / 10 > 10 则会使索引失效,应该改成 SELECT Col FROM tbl WHERE col > 10 * 10
5.2. 字符串不加单引号 - 存在隐式类型转换
在查询时,没有对字符串加单引号,MySQL 的查询优化器,会自动的进行类型转换,造成索引失效。
5.3. 用 or 连接没有索引的列 - 都失效
如果 or 前的条件中的列有索引,而后面的列中没有索引,那么涉及的索引都不会被用到。
示例,name 字段是索引列,而 createtime 不是索引列,中间是 or 进行连接是不走索引的 :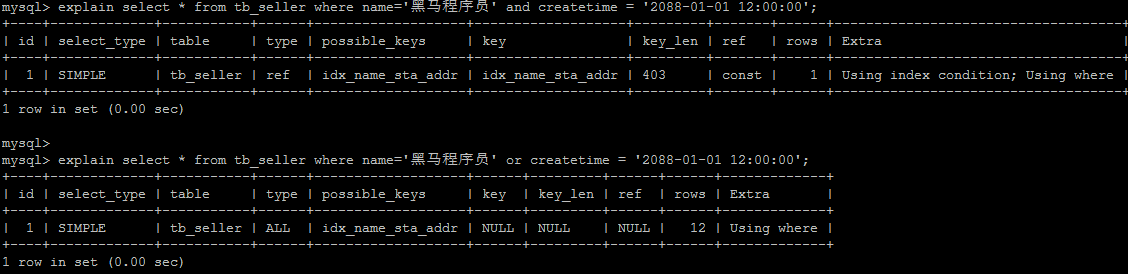
用 and 却可以
5.4. order by 没条件
没有过滤条件不走索引。group by 不加过滤条件还是可以使用索引的。
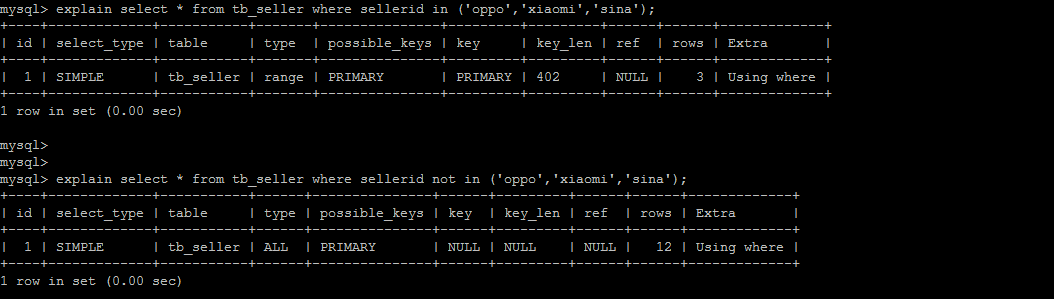
5.5. in 走索引, not in 索引失效
5.6. 以% 开头的 Like 模糊查询
如果仅仅是尾部模糊匹配,索引不会失效。如果是头部模糊匹配,索引失效。
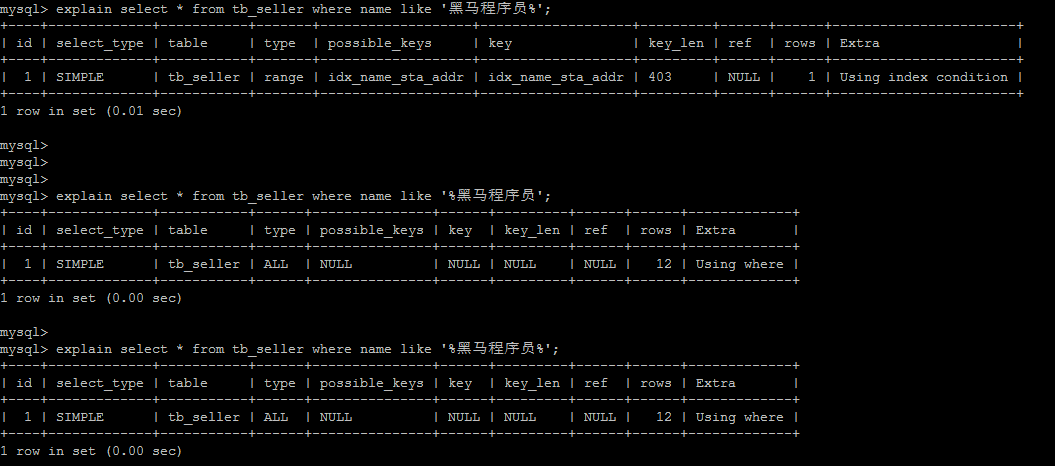
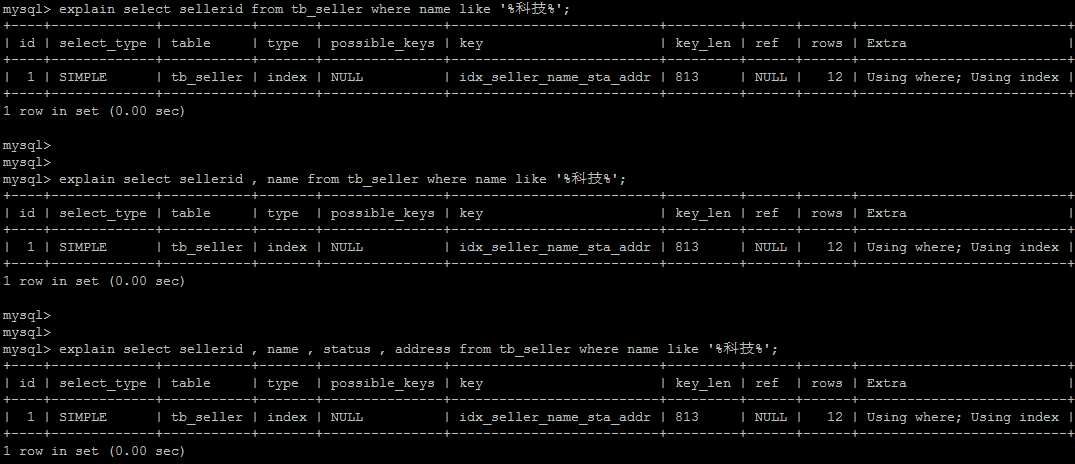
解决方案 :
通过覆盖索引来解决 ❕ ^zhh9w3
5.7. 如果 MySQL 评估使用索引比全表更慢
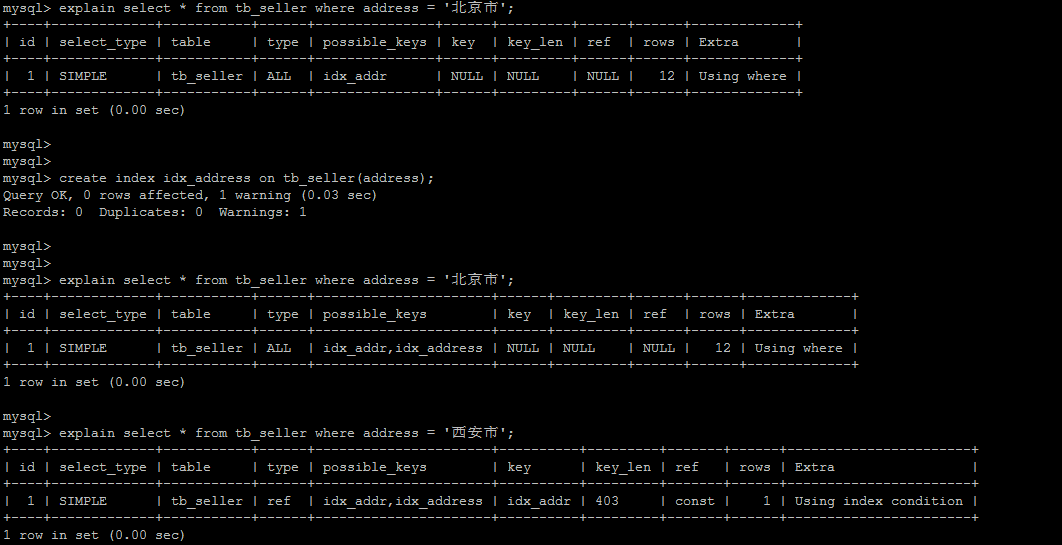
总共 13 条,北京市的有 10 条,接近全表扫描,优化器认为走索引还不如全表扫描,所以就不会走索引。而西安市就 1 条,走索引更快。
5.8. 复合索引
5.8.1. 未全值匹配
对索引中所有列都指定具体值,会使用索引,且跟字段的顺序无关
如果不是全值匹配,则需要遵守最左前缀法则。如果满足最左前缀,字段的顺序也可以改变。最左的意思是,复合索引中最左边的列必须存在,与位置无关。
5.8.2. 违反最左前缀法则 - 缺失最左列
如果索引了多列,要遵守最左前缀法则。指的是查询从索引的最左前列开始,并且不跳过索引中的列。
5.8.3. 出现跳跃某一列 - 只有最左列索引生效

5.8.4. 范围查询的右边 - 列失效
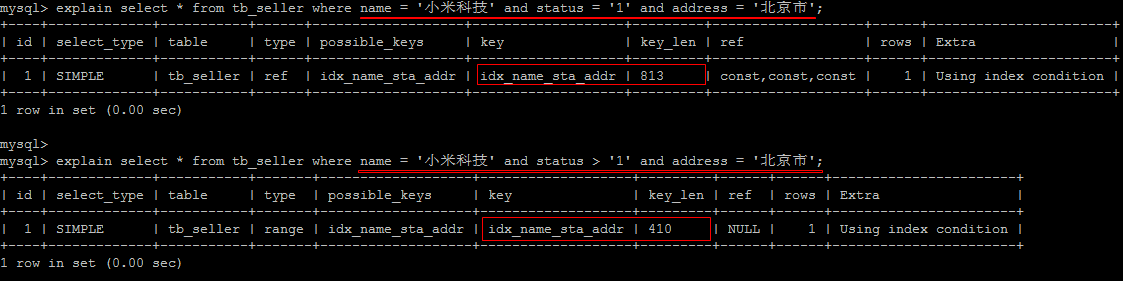
根据前面的两个字段 name , status 查询是走索引的,但是最后一个条件 address ,在范围条件的后面,所以没有用到索引。
5.9. 尽量使用覆盖索引 - 避免 select *
尽量使用覆盖索引(只访问索引的查询(索引列完全包含查询列)),减少 select * 。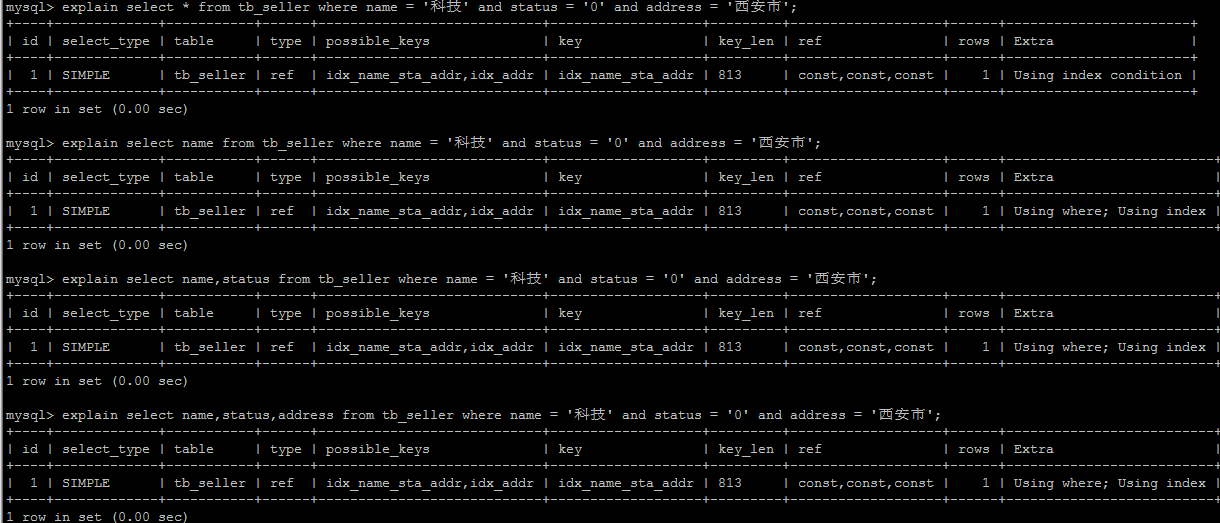
如果查询列,超出索引列,也会降低性能。

TIP :
using index :使用覆盖索引的时候就会出现
using where:在查找使用索引的情况下,需要回表去查询所需的数据
using index condition:查找使用了索引下推,但仍需要少量回表查询数据
using index ; using where:查找使用了索引,但是需要的数据都在索引列中能找到,所以不需要回表查询数据
❕ ^xkhbri
5.10. is Null/is Not Null- 以成本估算为准
如果某列建立索引,当进行 Select * from emp where depto is not null/is null。则可能会使索引失效。是因为 MySQL 进行了成本计算,如果 null 值太多,那么 is null 成本太高,还不如全表扫描,所以不会走索引,而 is not null 就会走索引。反之亦然。
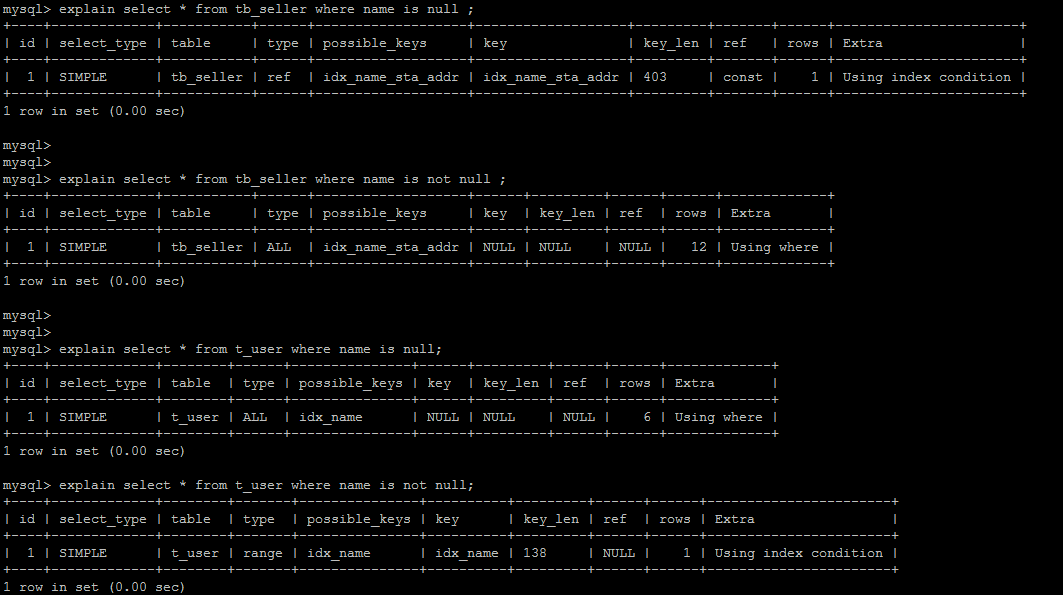
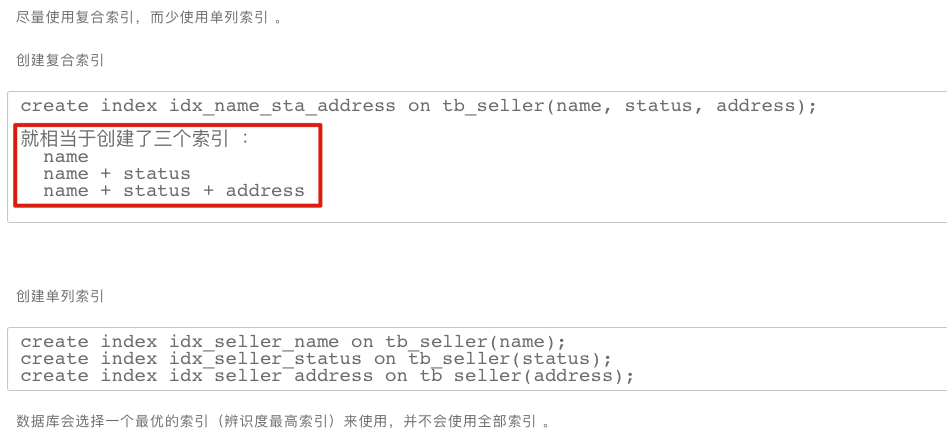
5.11. 尽量使用复合索引,而少使用单列索引
❕ ^9p2gib
6. 索引使用
6.1. 回表
通过辅助索引获取到主键索引值,然后再到主键索引查找数据的过程。
如果通过辅助索引查找的主键值超过主键索引的 80%,则 CBO 可能优化为全表扫描
6.2. 覆盖索引
尽量使用覆盖索引(只访问索引的查询(索引列完全包含查询列)),减少 select * 。
extra 为 using index :使用覆盖索引的时候就会出现
6.3. 索引下推
联合索引前面字段使用了范围查询 (比如大于小于或者 like),导致后面索引列无法使用时。利用复合索引和索引下推可以有效减少回表操作。
https://xiaolincoding.com/mysql/base/how_select.html#%E6%89%A7%E8%A1%8C%E5%99%A8
简称 ICP,Index Condition Pushdown(ICP) 是 MySQL 5.6 中新特性,是⼀种在存储引擎层使⽤索引过滤数据的⼀种优化⽅式,ICP 可以减少存储引擎访问基表的次数以及 MySQL 服务器访问存储引擎的次数。举个例⼦来说⼀下:我们需要查询 name 以 javacode35 开头的,性别为 1 的记录数,sql 如下:
select count(id) from test1 a where name like ‘javacode35%’ and sex = 1;
6.3.1. 一般过程
- ⾛ name 索引检索出以 javacode35 的第⼀条记录,得到记录的 id
- 利⽤ id 去主键索引中查询出这条记录 R1
- 判断 R1 中的 sex 是否为 1,然后重复上⾯的操作,直到找到所有记录为⽌。
上⾯的过程中需要⾛ name 索引以及需要回表操作。
6.3.2. 索引下推
所谓索引下推是指如果存在联合索引,使用了前面二级索引,查询出记录值之后,即使后面的索引字段无法使用,通过将判断工作从执行器下放到存储引擎进行判断,而无需再回表,或者减少回表的次数。
如果采⽤ ICP 的⽅式,我们可以这么做,创建⼀个 (name,sex) 的组合索引,查询过程如下:
- ⾛ (name,sex) 索引检索出以 javacode35 的第⼀条记录,可以得到 (name,sex,id),记做 R1
- 判断 R1.sex 是否为 1,然后重复上⾯的操作,直到找到所有记录为⽌
这个过程中不需要回表操作了,通过索引的数据就可以完成整个条件的过滤,速
度⽐上⾯的更快⼀些
当你的查询语句的执行计划里,出现了 Extra 为 Using index condition,那么说明使用了索引下推的优化。
6.3.3. 其他补充
现在有下面这条查询语句:
1 | |
联合索引当遇到范围查询 (>、<) 就会停止匹配,也就是 age 字段能用到联合索引,但是 reward 字段则无法利用到索引。具体原因这里可以看这篇:索引常见面试题(opens new window)
那么,不使用索引下推(MySQL 5.6 之前的版本)时,执行器与存储引擎的执行流程是这样的:
- Server 层首先调用存储引擎的接口定位到满足查询条件的第一条二级索引记录,也就是定位到 age > 20 的第一条记录;
- 存储引擎根据二级索引的 B+ 树快速定位到这条记录后,获取主键值,然后 进行回表操作,将完整的记录返回给 Server 层;
- Server 层在判断该记录的 reward 是否等于 100000,如果成立则将其发送给客户端;否则跳过该记录;
- 接着,继续向存储引擎索要下一条记录,存储引擎在二级索引定位到记录后,获取主键值,然后回表操作,将完整的记录返回给 Server 层;
- 如此往复,直到存储引擎把表中的所有记录读完。
可以看到,没有索引下推的时候,每查询到一条二级索引记录,都要进行回表操作,然后将记录返回给 Server,接着 Server 再判断该记录的 reward 是否等于 100000。
而使用索引下推后,判断记录的 reward 是否等于 100000 的工作交给了存储引擎层,过程如下 :
- Server 层首先调用存储引擎的接口定位到满足查询条件的第一条二级索引记录,也就是定位到 age > 20 的第一条记录;
- 存储引擎定位到二级索引后,先不执行回表 操作,而是先判断一下该索引中包含的列(reward 列)的条件(reward 是否等于 100000)是否成立。如果 条件不成立,则直接 跳过该二级索引。如果 成立,则 执行回表 操作,将完成记录返回给 Server 层。
- Server 层在判断其他的查询条件(本次查询没有其他条件)是否成立,如果成立则将其发送给客户端;否则跳过该记录,然后向存储引擎索要下一条记录。
- 如此往复,直到存储引擎把表中的所有记录读完。
可以看到,使用了索引下推后,虽然 reward 列无法使用到联合索引,但是因为它包含在联合索引(age,reward)里,所以直接在存储引擎过滤出满足 reward = 100000 的记录后,才去执行回表操作获取整个记录。相比于没有使用索引下推,节省了很多回表操作。
当你发现执行计划里的 Extr 部分显示了 “Using index condition”,说明使用了索引下推。
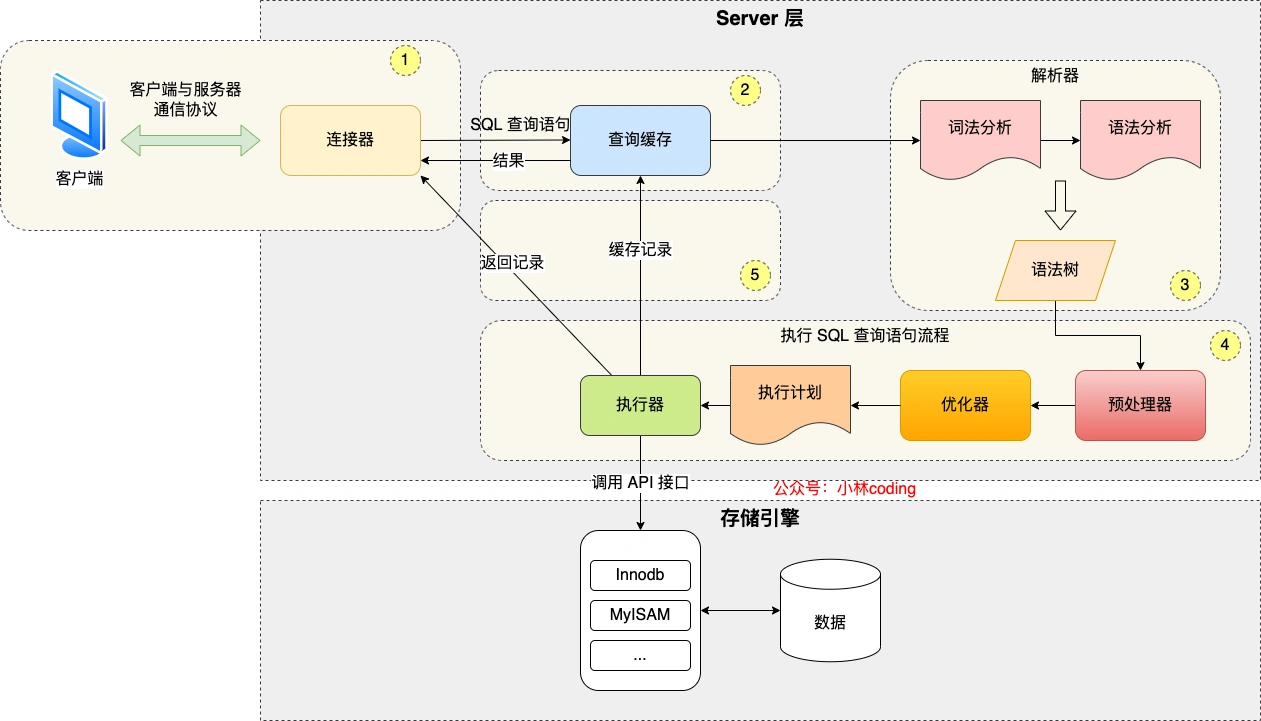
7. 索引分析
7.1. 查看索引
1 | |

1 | |
8. 索引优先级
8.1. 多个索引优先级是如何匹配的
- 主键(唯一索引)匹配
- 全值匹配(单值匹配)
- 最左前缀匹配
- 范围匹配
- 索引扫描
- 全表扫描
9. 实战经验
10. 参考与感谢
10.1. 为什么大家说 mysql 数据库单表最大两千万?依据是啥?
https://ost.51cto.com/posts/11397
10.2. 黑马
10.2.1. 视频
https://www.bilibili.com/video/BV1zJ411M7TB?p=4&vd_source=c5b2d0d7bc377c0c35dbc251d95cf204
10.2.2. 资料
1 | |
https://www.cnblogs.com/aspwebchh/p/6652855.html
https://blog.csdn.net/linminqin/article/details/44342205
https://www.cnblogs.com/aspnethot/articles/1504082.html
10.3. 小林 coding
https://xiaolincoding.com/mysql/lock/how_to_lock.html#gap-lock
 微信
微信 支付宝
支付宝

