
框架源码专题-Redis-5、案例落地实战
1. 键值设计

[[Redis高级篇之最佳实践.md]]
2. 布隆过滤器 -BloomFilter
❕ ^o440ad
2.1. 是什么
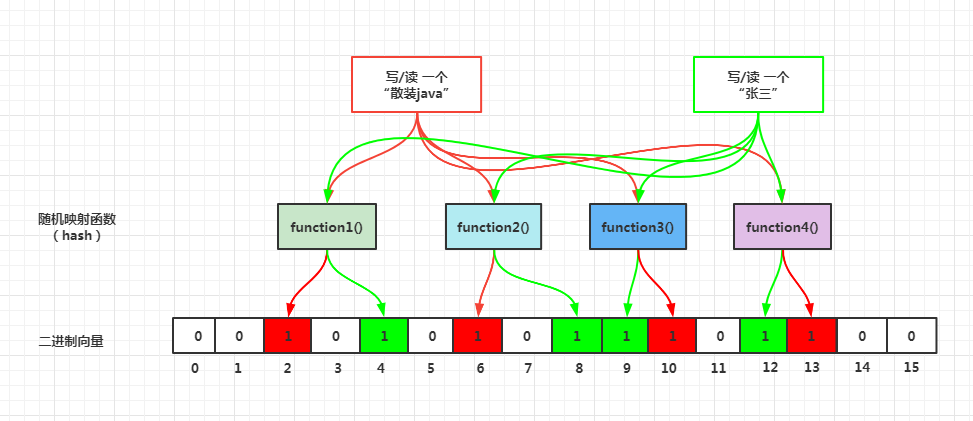
布隆过滤器(Bloom Filter)是 1970 年由布隆提出的。它实际上是一个很长的 二进制向量 和 一系列随机映射函数 。布隆过滤器可以用于 检索一个元素是否在一个集合中 。它的优点是 空间效率和查询时间都比一般的算法要好的多 ,缺点是有一定的 误识别率和删除困难 。
可以理解为:有个二进制的 集合 ,里面存放的 0 和 1,0 代表不存在,1 代表存在,可以通过一些定义好的 方法 快速判断元素是否在集合中。内部逻辑如下图展示
2.2. 作用
由于布隆过滤器的特性,能够判断一个数据 可能在集合中 ,和一个数据 绝对不在集合中 ,所以他可以用于以下场景
- 网页 URL 的去重(爬虫,避免爬取相同的 URL 地址)
- 垃圾邮件的判别
- 集合重复元素的判别
- 查询加速(比如基于 key-value 的存储系统)
- 解决缓存穿透,使用 BloomFilter 来减少不存在的行或列的磁盘查找。温故知新:[[框架源码专题-Redis-1、基本原理#5.1. 缓存穿透]]
目的:减少内存占用
方式:不保存数据信息,只是在内存中做一个是否存在的标记 flag

2.3. 原理
布隆过滤器 (Bloom Filter) 是一种专门用来解决去重问题的高级数据结构。
实质就是一个大型 位数组 和几个不同的无偏 hash 函数 (无偏表示分布均匀)。由一个初值都为零的 bit 数组和多个哈希函数构成,用来快速判断某个数据是否存在。但是跟 HyperLogLog 一样,它也一样有那么一点点不精确,也存在一定的误判概率
2.3.1. 添加 key
2.3.1.1. 添加 key 时
使用多个 hash 函数对 key 进行 hash 运算得到一个整数索引值,对位数组长度进行取模运算得到一个位置,每个 hash 函数都会得到一个不同的位置,将这几个位置都置 1就完成了 add 操作。
2.3.1.2. 查询 key 时⭐️🔴
只要有其中一位是 0 就表示这个 key 不存在,但如果都是 1,则不一定存在对应的 key。结论:有,是可能有;无,是肯定无
2.3.2. 为什么不精确
当有变量被加入集合时,通过 N 个映射函数将这个变量映射成位图中的 N 个点,
把它们置为 1(假定有两个变量都通过 3 个映射函数)。
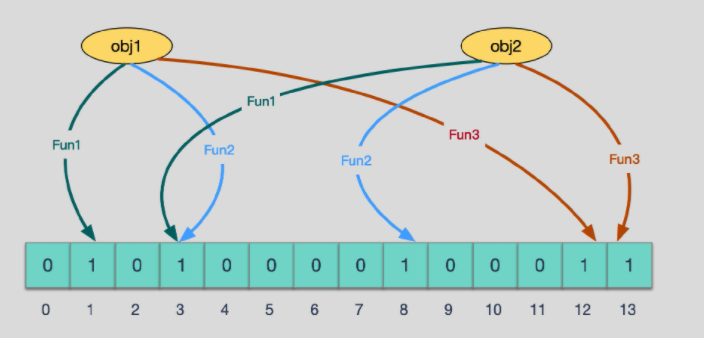
查询某个变量的时候我们只要看看这些点是不是都是 1,就可以大概率知道集合中有没有它了
如果这些点,有任何一个为零则被查询变量一定不在,
如果都是 1,则被查询变量很可能存在,
为什么说是可能存在,而不是一定存在呢?那是因为映射函数本身就是散列函数,散列函数是会有碰撞的。(见上图 3 号坑两个对象都 1)
2.4. 布隆过滤器的用法
基于别的轮子
以下轮子可以使用
- Guava 示例 GuavaBloomFilterTest
- HuTool
- Redisson 示例 RedissonDemoTest
- 自己实现一个示例 BulkBloomFilter
2.5. 如何解决布隆过滤器无法删除数据的问题
- 升级版的布隆过滤器(Counting Bloom Filter) 其原理为:
- 原理就是把位图的位升级为计数器 (Counter)
- 添加元素, 就给对应的 Counter 分别 +1
- 删除元素, 就给对应的 Counter 分别减一
- 用多出几倍存储空间的代价, 来实现删除功能
- 布谷鸟过滤器(Cuckoo filter)
2.6. 使用场景
2.6.1. 解决缓存穿透的问题
❕ ^w0pylf

把已存在数据的 key 存在布隆过滤器中,相当于 redis 前面挡着一个布隆过滤器。
当有新的请求时,先到布隆过滤器中查询是否存在:
如果布隆过滤器中不存在该条数据则直接返回;
如果布隆过滤器中已存在,才去查询缓存 redis,如果 redis 里没查询到则再查询 Mysql 数据库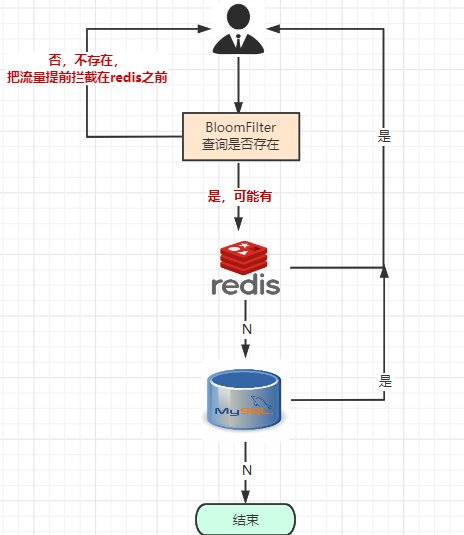
2.6.2. 黑名单校验
发现存在黑名单中的,就执行特定操作。比如:识别垃圾邮件,只要是邮箱在黑名单中的邮件,就识别为垃圾邮件。
假设黑名单的数量是数以亿计的,存放起来就是非常耗费存储空间的,布隆过滤器则是一个较好的解决方案。
把所有黑名单都放在布隆过滤器中,在收到邮件时,判断邮件地址是否在布隆过滤器中即可。
2.6.3. 安全网站判断
2.7. 优缺点

2.8. 与 bitmap 的区别
https://developer.aliyun.com/article/930143#slide-6
https://juejin.cn/s/%E5%B8%83%E9%9A%86%E8%BF%87%E6%BB%A4%E5%99%A8%E5%92%8Cbitmap%E5%8C%BA%E5%88%AB
3. 缓存击穿 - 高并发聚划算案例
[[框架源码专题-Redis-1、基本原理#^ce1aw6]]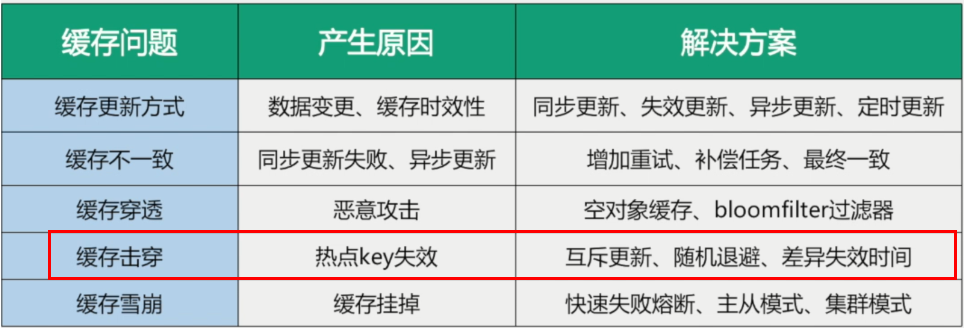
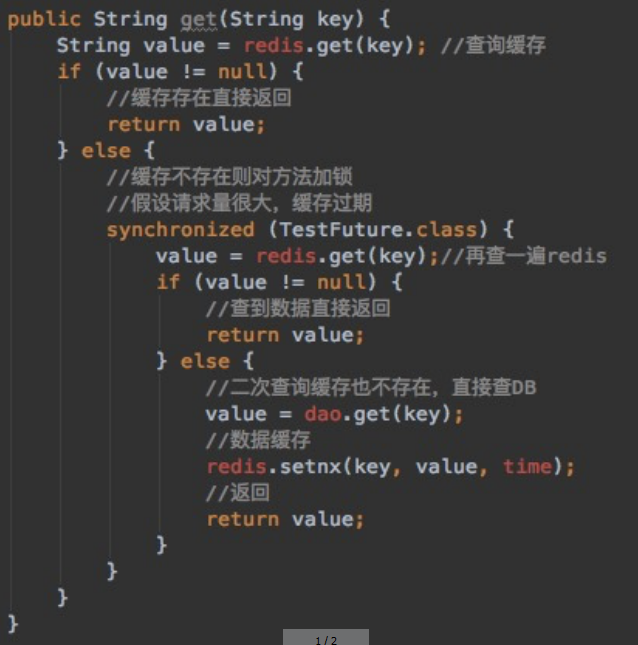
3.1. 互斥检查锁
❕ ^2kv736
多个线程同时去查询数据库的这条数据,那么我们可以在第一个查询数据的请求上使用一个互斥锁来锁住它。
其他的线程走到这一步拿不到锁就等着,等第一个线程查询到了数据,然后做缓存。后面的线程进来发现已经有缓存了,就直接走缓存。
3.2. 差异化失效时间
❕ ^f2c38u

4. BigKey
4.1. MoreKey

4.1.1. 禁用 keys *、flashdb、flushall


说明:对于 FLUSHALL 命令,需要设置配置文件中 appendonly no,否则服务器无法启动。rename-command 命名无法直接对线上集群生效。如果需要使用 rename-command,必须重启集群。所以建议一开始,就将该配置配置好。
4.1.2. scan 命令
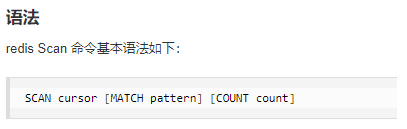

SCAN 命令是一个基于游标的迭代器,每次被调用之后,都会向用户返回一个新的游标,用户在下次迭代时需要使用这个新游标作为 SCAN 命令的游标参数,以此来延续之前的迭代过程。
SCAN 返回一个包含两个元素的数组,
第一个元素是用于进行下一次迭代的新游标,
第二个元素则是一个数组,这个数组中包含了所有被迭代的元素。如果新游标返回零表示迭代已结束。
SCAN 的遍历顺序
非常特别,它不是从第一维数组的第零位一直遍历到末尾,而是采用了高位进位加法来遍历。之所以使用这样特殊的方式进行遍历,是考虑到字典的扩容和缩容时避免槽位的遍历重复和遗漏。
4.2. BigKey⭐️🔴
4.2.1. 多大算 big
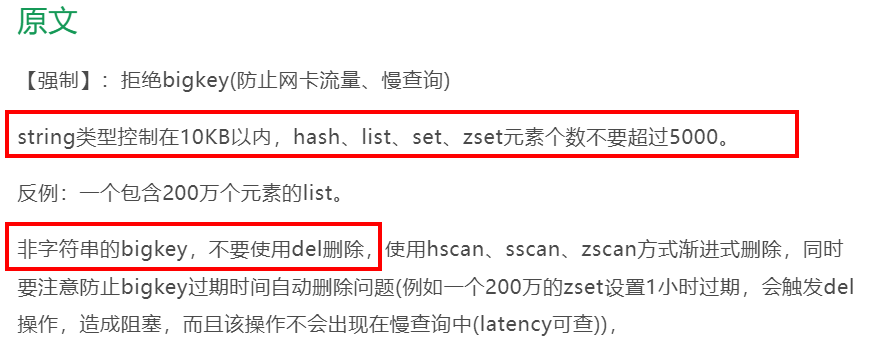
4.2.2. 哪些危害

4.2.3. 如何产生

4.2.4. 如何发现
4.2.4.1. redis-cli –bigkeys
redis-cli --bigkeys -a 111111 redis-cli -h 127.0.0.1 -p 6379 -a 111111 --bigkeys
每隔 100 条 scan 指令就会休眠 0.1s,ops 就不会剧烈抬升,但是扫描的时间会变长redis-cli -h 127.0.0.1 -p 7001 –-bigkeys -i 0.1
4.2.4.2. MEMORY USAGE key

4.2.5. 如何删除
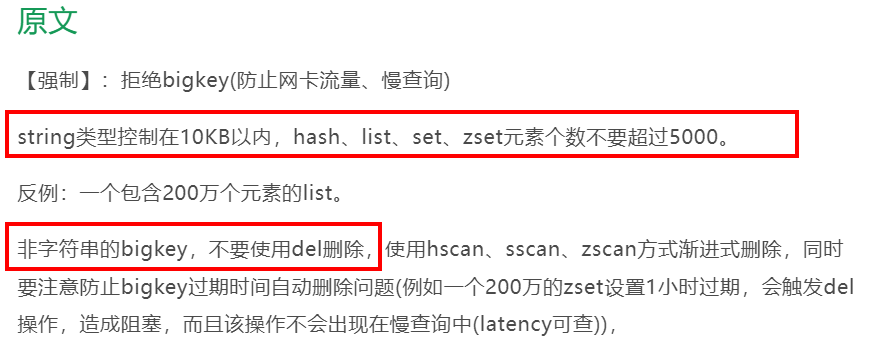
4.2.5.1. String
一般用 del,过于庞大用 unlink
4.2.5.2. hash
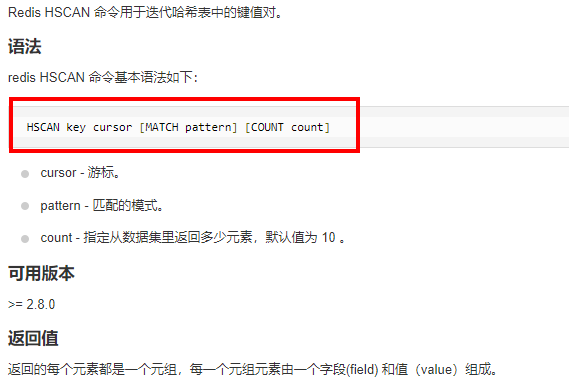
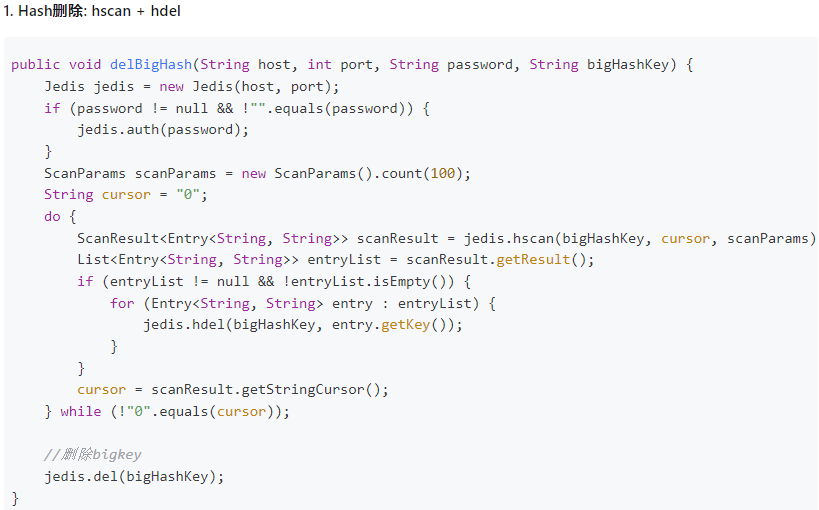
4.2.5.3. list
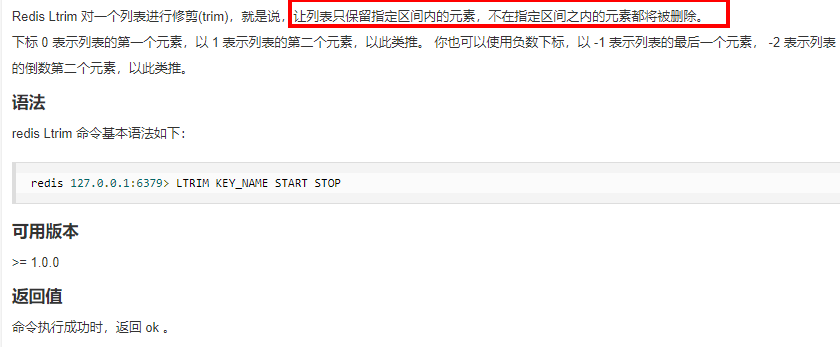
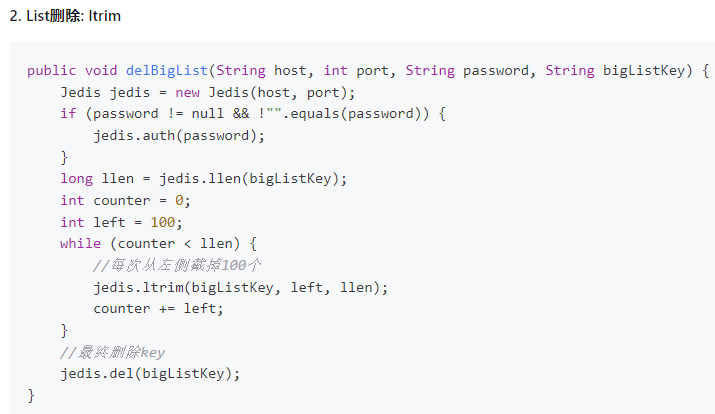
4.2.5.4. set

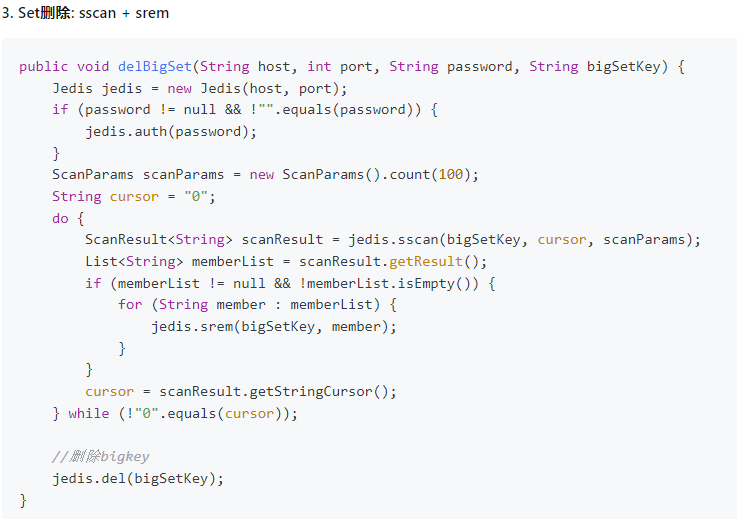
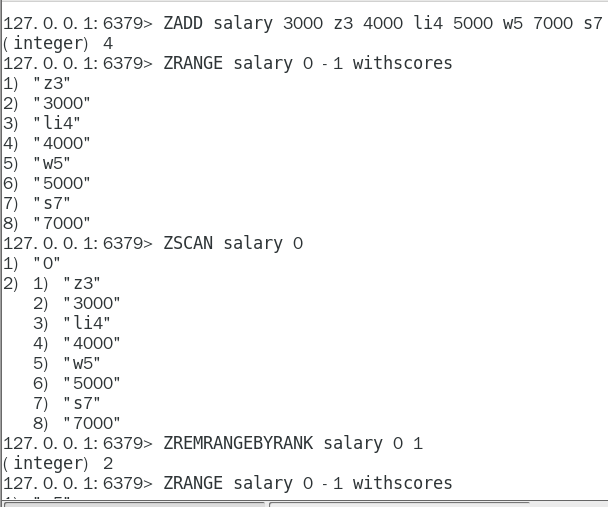
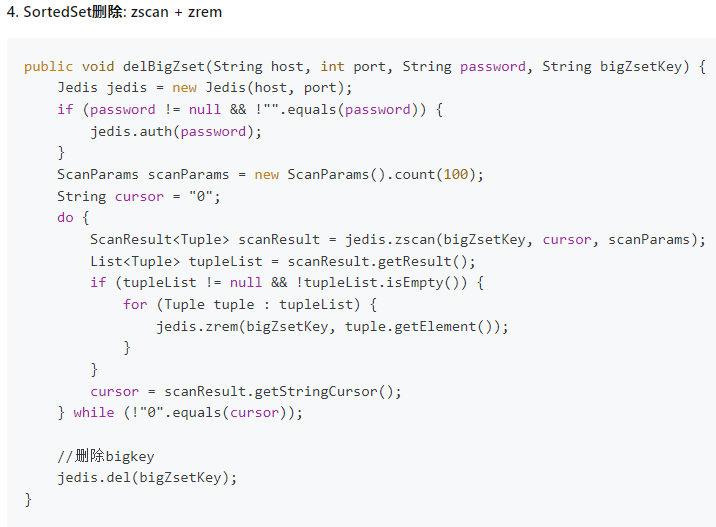
4.2.5.5. zset
4.2.6. BigKey 生产调优
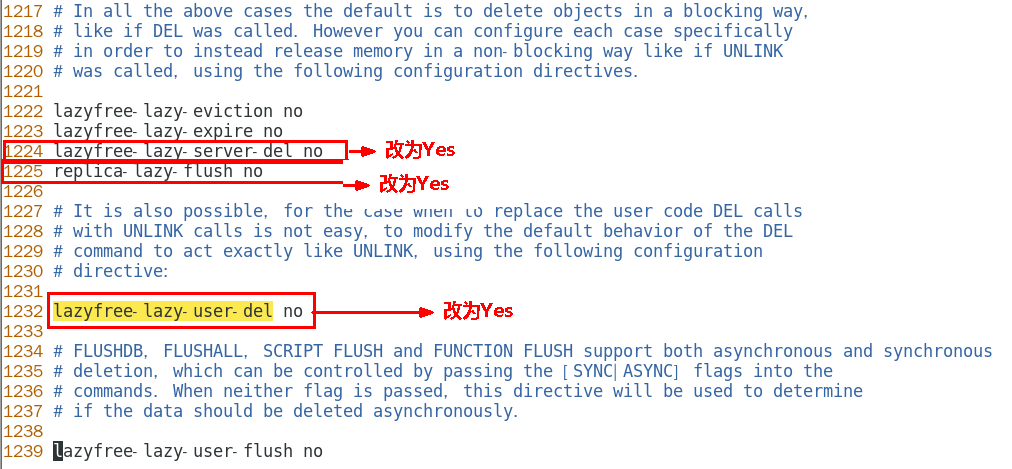
redis.conf 中配置 LAZY FREEING
4.2.6.1. 阻塞和非阻塞删除命令

4.2.6.2. 优化配置
❕ ^o2bbla
5. 实战经验
6. 参考与感谢
6.1. 散装 java 公众号
https://doc.bulkall.top/
https://gitee.com/bulkall/bulk-demo.git
 微信
微信 支付宝
支付宝

