
分布式专题-6、服务注册与发现-Nacos
1. 注解原理
https://www.cnblogs.com/lm970585581/p/13066729.html
从 Edgware 版本开始,可以不加@EnableDiscoveryClient 注解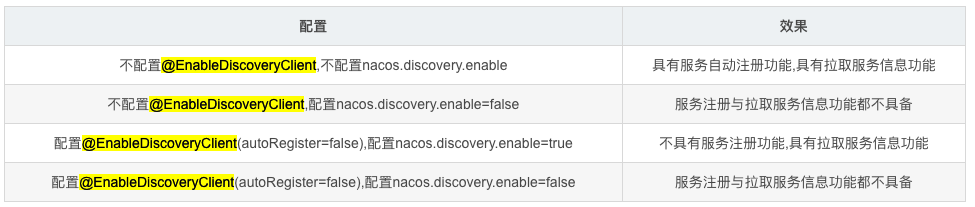
2. 注册中心
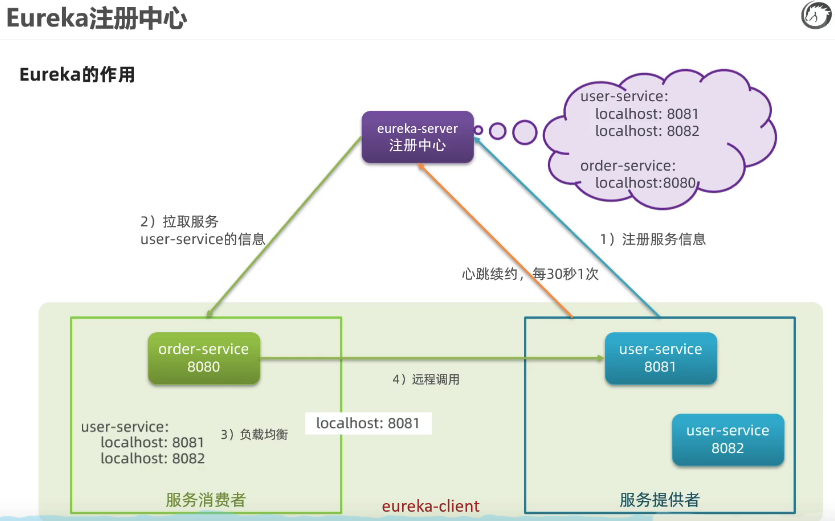
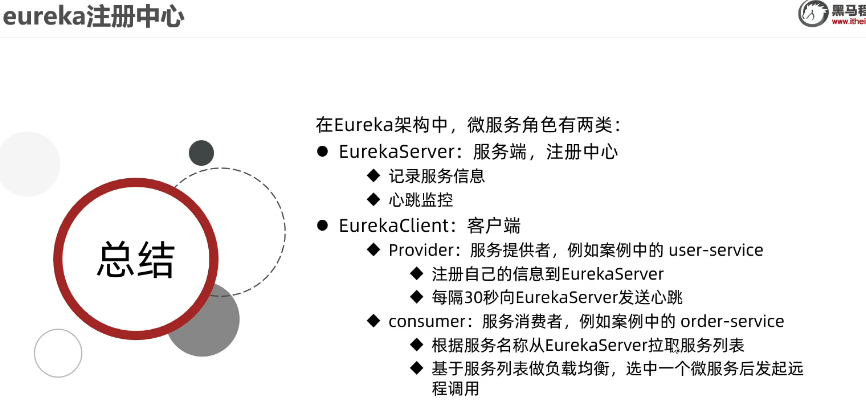
服务注册: 当服务启动通过 Rest 请求的方式向 Nacos Server 注册自己的服务
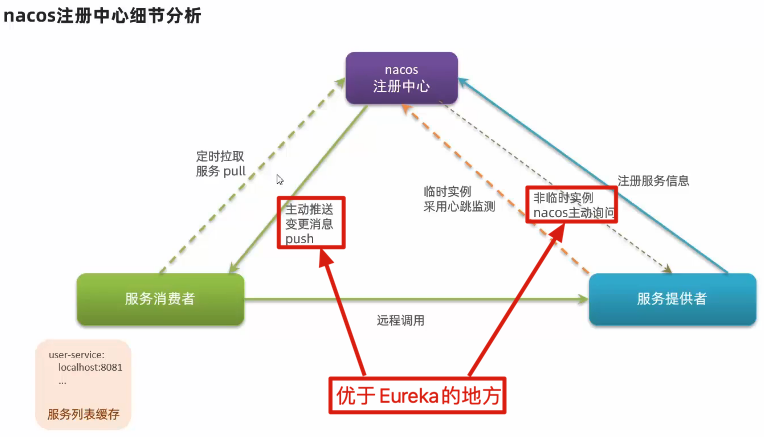
服务心跳:Nacos Client 会维护一个定时心跳持续通知 Nacos Server , 默认 5s 一次,如果 Nacos Server超过了 15 秒没有接收心跳,会将服务健康状态设置 false(拉取的时候会忽略),如果超过了 30 秒没有接收心跳剔除服务。
服务发现:Nacos Client 会有一个定时任务,实时去 Nacos Server 拉取健康服务,并缓存在本地一份。如果有变更,Nacos Server 也会主动推送。
服务停止:Nacos Client 会主动通过 Rest 请求 Nacos Server 发送一个注销的请求
2.1. 注册流程
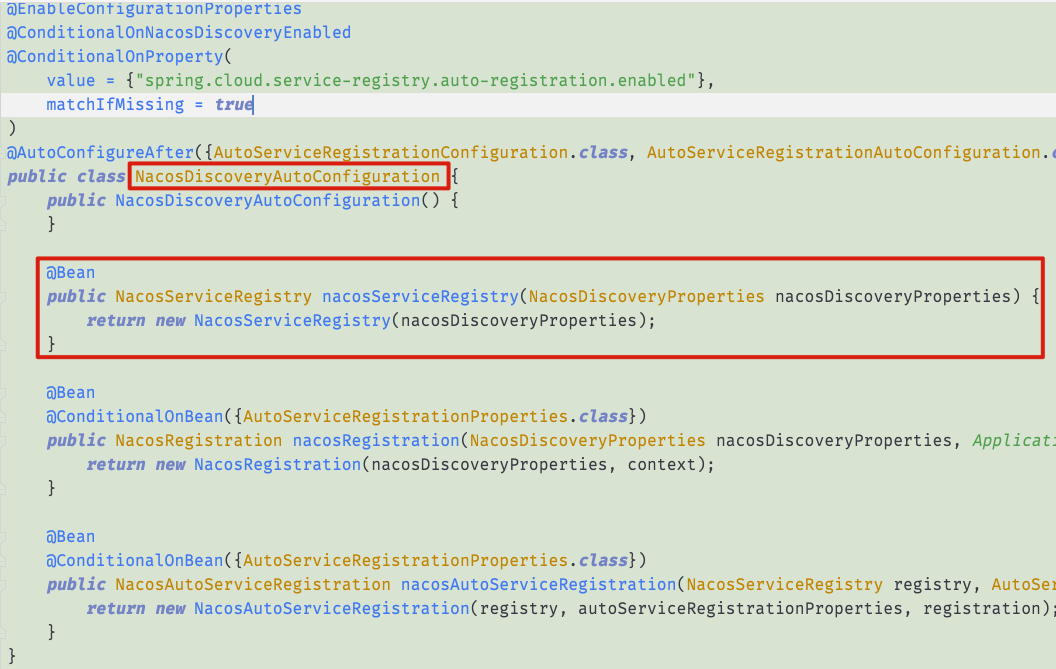
2.2. 有拉有推
3. 配置中心
3.1. 优点
集中管理服务的配置、提高维护性、时效性、安全性
3.2. 配置内容
有哪些东西可以作为配置?
比方说,数据库连接 Url,缓存连接 url 字符串,数据库的用户名,密码都可以作为配置的字符串,除此之外,还有一些可以==动态调整的参数==,比方说,客户端的超时设置限流规则和降级开关,流量的动态调度,比方说某个功能只是针对某个地区用户,还有某个功能只在大促的时段开放,如果这种需要通过静态的方式去配置或者发布的方式去配置,那么响应速度是非常慢,可能对业务存在风险,如果有一套集中式的配置中心,只需要相关人员在配置中心动态去调整参数,就基本上可以实时或准实时去调整相关对应的业务。所以配置中心在微服务中算是一个举足轻重的组件。
3.3. 配置读取
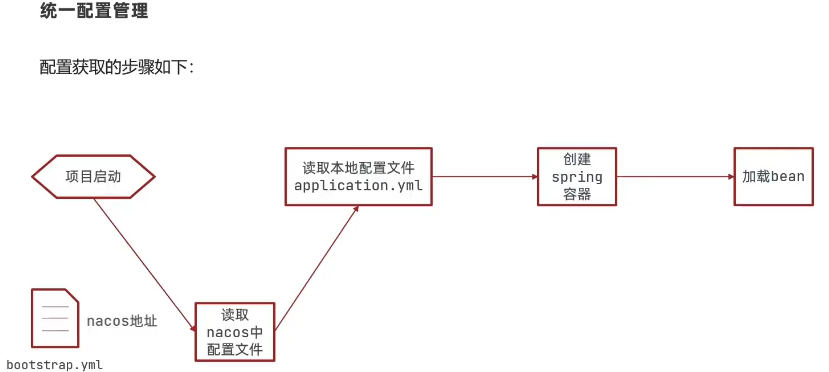
3.4. 配置更新
https://ost.51cto.com/posts/13172
https://www.cnkirito.moe/nacos-and-longpolling/
3.4.1. 推与拉模型
客户端与配置中心的数据交互方式其实无非就两种,要么推 push,要么拉 pull
3.4.1.1. 推模型
客户端与服务端建立 TCP 长连接,当服务端配置数据有变动,立刻通过建立的长连接将数据推送给客户端。
优势:长链接的优点是实时性,一旦数据变动,立即推送变更数据给客户端,而且对于客户端而言,这种方式更为简单,只建立连接接收数据,并不需要关心是否有数据变更这类逻辑的处理。
弊端:长连接可能会因为网络问题,导致不可用,也就是俗称的 假死。连接状态正常,但实际上已无法通信,所以要有的心跳机制 KeepAlive 来保证连接的可用性,才可以保证配置数据的成功推送。
3.4.1.2. 拉模型
客户端主动的向服务端发请求拉配置数据,常见的方式就是轮询,比如每 3s 向服务端请求一次配置数据。
轮询的优点是实现比较简单。但弊端也显而易见,轮询无法保证数据的实时性,什么时候请求?间隔多长时间请求一次?都是不得不考虑的问题,而且轮询方式对服务端还会产生不小的压力。
3.4.2. 长轮询与轮询
https://www.cnkirito.moe/nacos-and-longpolling/
长轮训典型的场景有: 扫码登录、扫码支付。
https://juejin.cn/post/6844904019278692360
3.4.3. 长轮询 + 拉取⭐️🔴
首先,Nacos 是采用长轮询的方式向 Nacos Server 端发起配置更新查询的功能。所谓长轮询就是客户端发起一次轮训请求到服务端,当服务端配置没有任何变更的时候,这个连接一直打开。直到服务端有配置或者连接超时后返回。
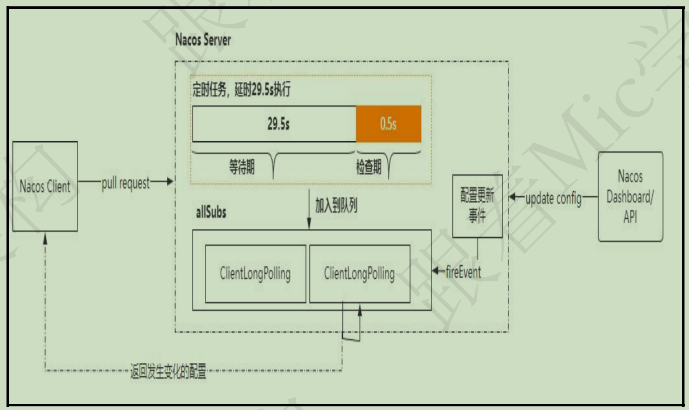
Nacos Client 端需要获取服务端变更的配置,前提是要有一个比较,也就是拿客户端本地的配置信息和服务端的配置信息进行比较。一旦发现和服务端的配置有差异,就表示服务端配置有更新,于是把更新的配置拉到本地。
在这个过程中,有可能因为客户端配置比较多,导致比较的时间较长,使得配置同步较慢的问题。于是 Nacos 针对这个场景,做了两个方面的优化。
减少网络通信的数据量
客户端把需要进行比较的配置进行分片,每一个分片大小是 3000,也就是说,每次最多拿 3000 个配置去 Nacos Server 端进行比较。
分阶段进行比较和更新
第一阶段,客户端把这 3000 个配置的 key 以及对应的 value 值的 md5 拼接成一个字符串,然后发送到 Nacos Server 端进行判断,服务端会逐个比较这些配置中 md5 不同的 key,把存在更新的 key 返回给客户端。
第二阶段,客户端拿到这些变更的 key,循环逐个去调用服务单获取这些 key 的 value 值。
这两个优化,核心目的是减少网络通信数据包的大小,把一次大的数据包通信拆分成了多次小的数据包通信。虽然会增加网络通信次数,但是对整体的性能有较大的提升。最后,再采用长连接这种方式,既减少了 pull 轮询次数,又利用了长连接的优势,很好的实现了配置的动态更新同步功能。
源码: http://blog.itpub.net/69908605/viewspace-2657617/
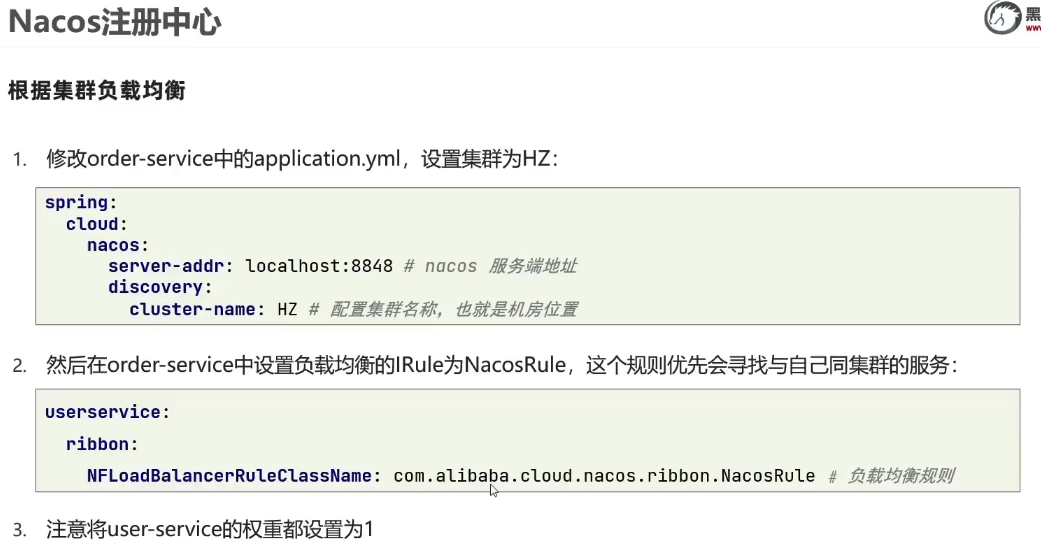
4. NacosRule 负载均衡

5. CP or AP
Nacos 集群默认采用 AP 方式,当集群中存在非临时实例时,采用 CP 模式;Eureka 采用 AP 方式
6. 环境隔离
6.1. 配置隔离

以命名空间区分各个微服务,以分组区分不同的开发环境
6.2. 注册隔离

7. 面试题
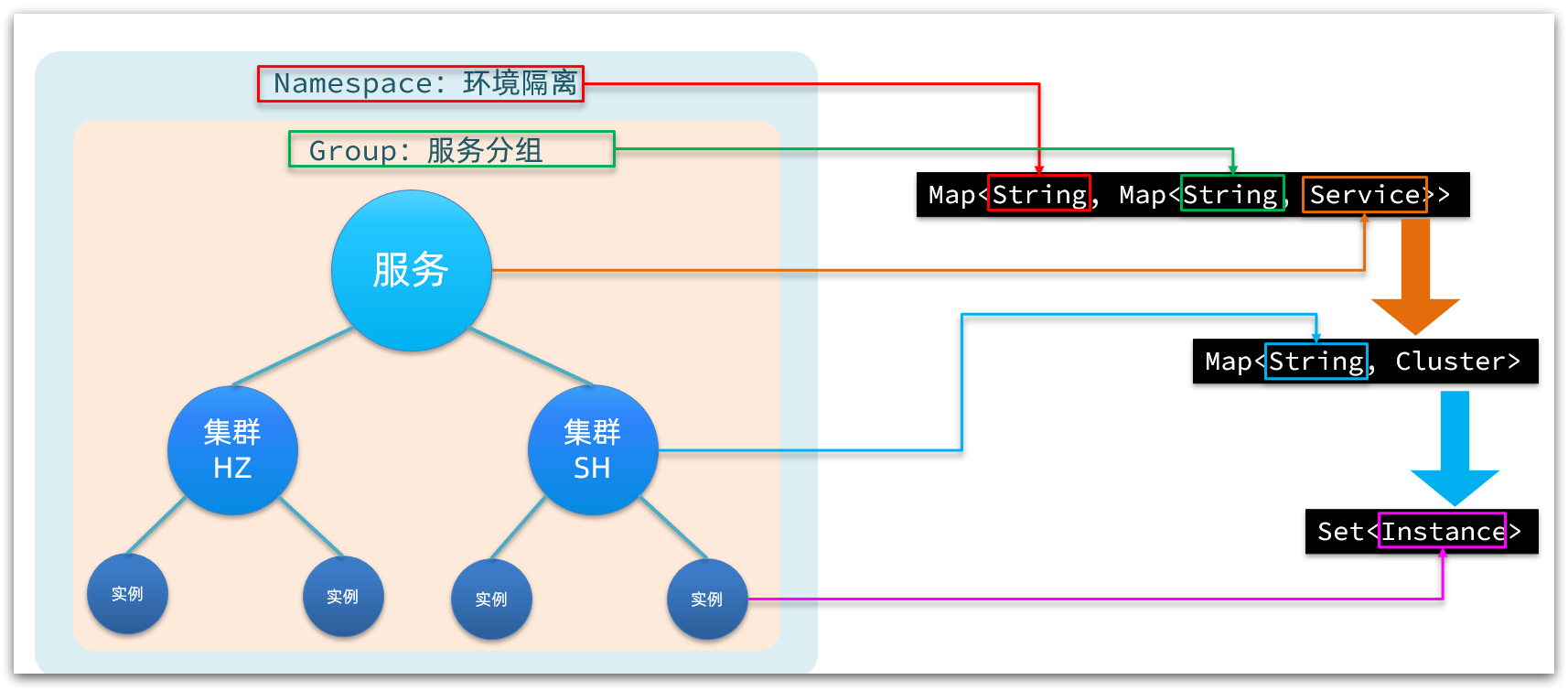
7.1. Nacos 的服务注册表结构是怎样的⭐️🔴
Nacos 采用了==数据的分级存储模型==,最外层是 Namespace,用来隔离环境。然后是 Group,用来对服务分组。接下来就是服务(Service)了,==一个服务包含多个实例,但是可能处于不同机房,因此 Service 下有多个集群(Cluster)==,Cluster 下是不同的实例(Instance)。 ^i099uh
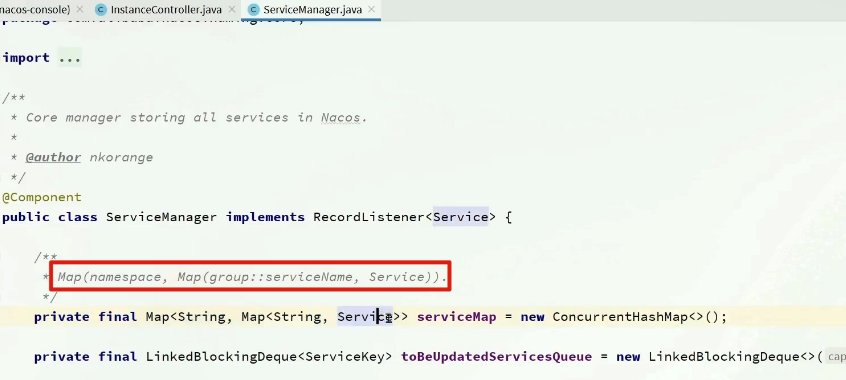
对应到 Java 代码中,Nacos 采用了一个多层的 Map 来表示。结构为 Map<String, Map<String, Service>>,其中最外层 Map 的 key 就是 namespaceId,值是一个 Map。内层 Map 的 key 是 group 拼接 serviceName,值是 Service 对象。Service 对象内部又是一个 Map,key 是 集群名称,值是 Cluster 对象。而 Cluster 对象内部维护了 Instance 的集合。


7.2. Nacos 如何支撑阿里内部数十万服务注册压力?
Nacos 内部接收到注册的请求时,不会立即写数据,而是将服务注册的任务放入一个阻塞队列就立即响应给客户端。然后利用线程池读取阻塞队列中的任务,异步来完成实例更新,从而提高并发写能力。
7.3. Nacos 如何避免并发读写冲突问题?
Nacos 在更新实例列表时,会采用 CopyOnWrite 技术,首先将旧的实例列表拷贝一份,然后更新拷贝的实例列表,再用更新后的实例列表来覆盖旧的实例列表。
这样在更新的过程中,就不会对读实例列表的请求产生影响,也不会出现脏读问题了。
7.4. Nacos 如何保证并发写的安全性?
首先,在注册实例时,会对 service 加锁,不同 service 之间本身就不存在并发写问题,互不影响。相同 service 时通过锁来互斥。并且,在更新实例列表时,是基于异步的线程池来完成,而线程池的线程数量为 1.
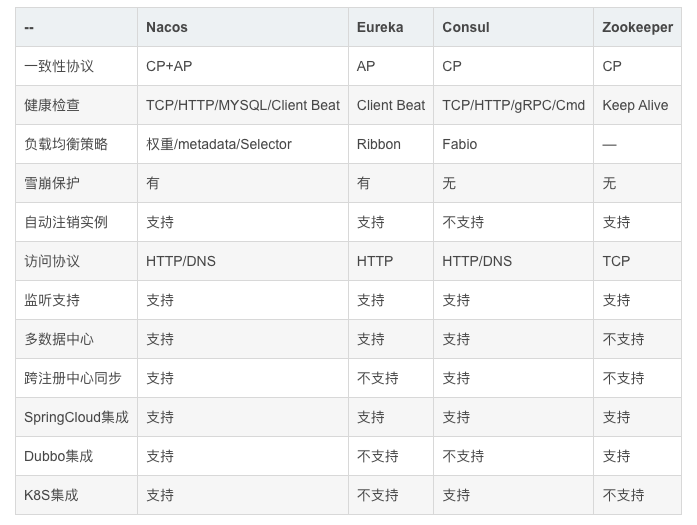
7.5. Nacos 与 Eureka 的区别有哪些?
https://www.bilibili.com/video/BV1LQ4y127n4?p=23&vd_source=c5b2d0d7bc377c0c35dbc251d95cf204
Nacos 与 Eureka 有相同点,也有不同之处,可以从以下几点来描述:
- 接口方式:Nacos 与 Eureka 都对外暴露了 Rest 风格的 API 接口,用来实现服务注册、发现等功能
- 实例类型:Nacos 的实例有永久和临时实例之分;而 Eureka 只支持临时实例
- 健康检测:Nacos 对临时实例采用心跳模式检测,对永久实例采用主动请求来检测;Eureka 只支持心跳模式
- 服务发现:Nacos 支持定时拉取和订阅推送两种模式;Eureka 只支持定时拉取模式

每 30 秒向 EurekaServer 发送心跳
8. 实战经验
9. 参考与感谢
面试专题-6、分布式组件 微信
微信 支付宝
支付宝

