
框架源码专题-RabbitMQ-1、基本原理
1. 消息可靠性
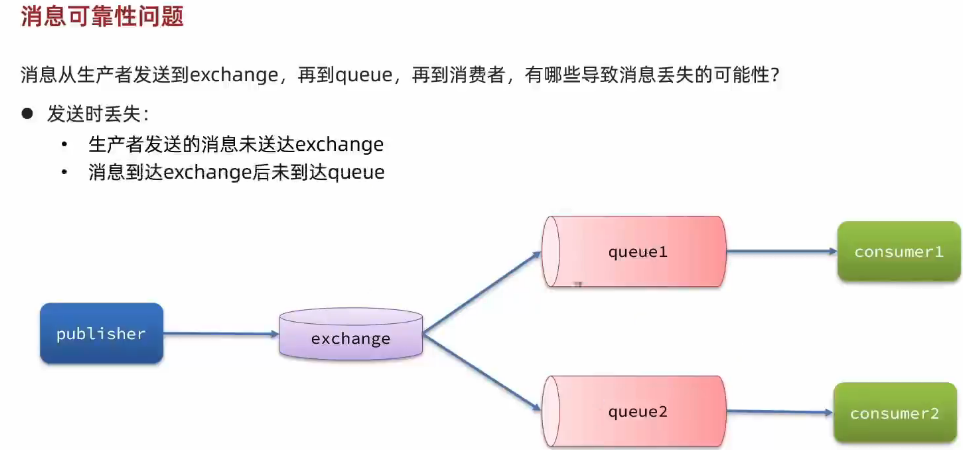
1.1. 生产者消息确认
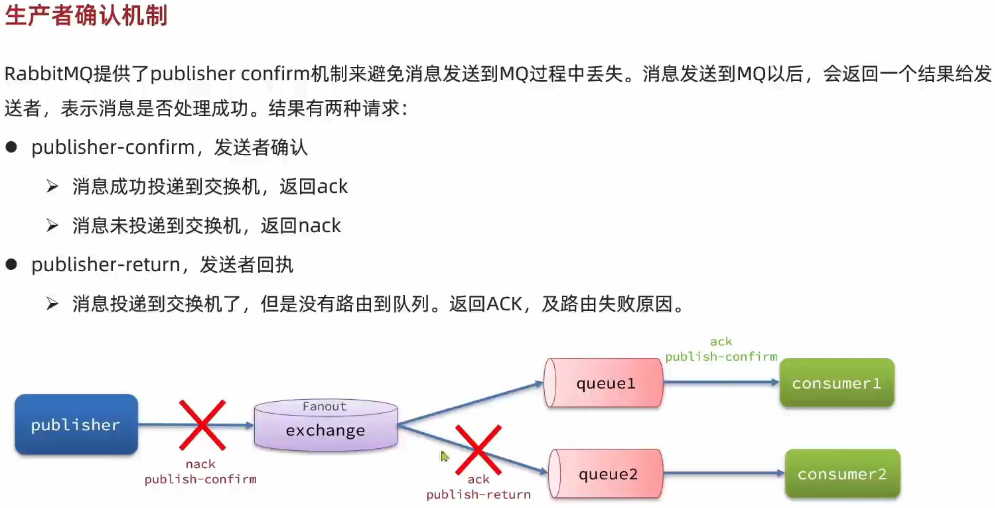

1.1.1. 修改配置
首先,修改 publisher 服务中的 application.yml 文件,添加下面的内容:
1 | |
说明:
publish-confirm-type:开启 publisher-confirm,这里支持两种类型:simple:同步等待 confirm 结果,直到超时correlated:异步回调,定义 ConfirmCallback,MQ 返回结果时会回调这个 ConfirmCallback
publish-returns:开启 publish-return 功能,同样是基于 callback 机制,不过是定义 ReturnCallbacktemplate.mandatory:定义消息路由失败时的策略。true,则调用 ReturnCallback;false:则直接丢弃消息
1.1.2. 定义 ReturnCallback -ApplicationContextAware
每个 RabbitTemplate 只能配置一个 ReturnCallback,因此需要在项目加载时配置:
修改 publisher 服务,添加一个:
1 | |
1.1.3. 定义 ConfirmCallback
ConfirmCallback 可以在发送消息时指定,因为每个业务处理 confirm 成功或失败的逻辑不一定相同。
1 | |
1.2. 消息持久化
生产者确认可以确保消息投递到 RabbitMQ 的队列中,但是消息发送到 RabbitMQ 以后,如果突然宕机,也可能导致消息丢失。
要想确保消息在 RabbitMQ 中安全保存,必须开启消息持久化机制。
- 交换机持久化
- 队列持久化
- 消息持久化
默认情况下,由 SpringAMQP 声明的交换机、队列、消息都是持久化的。
1.3. 消费者消息确认
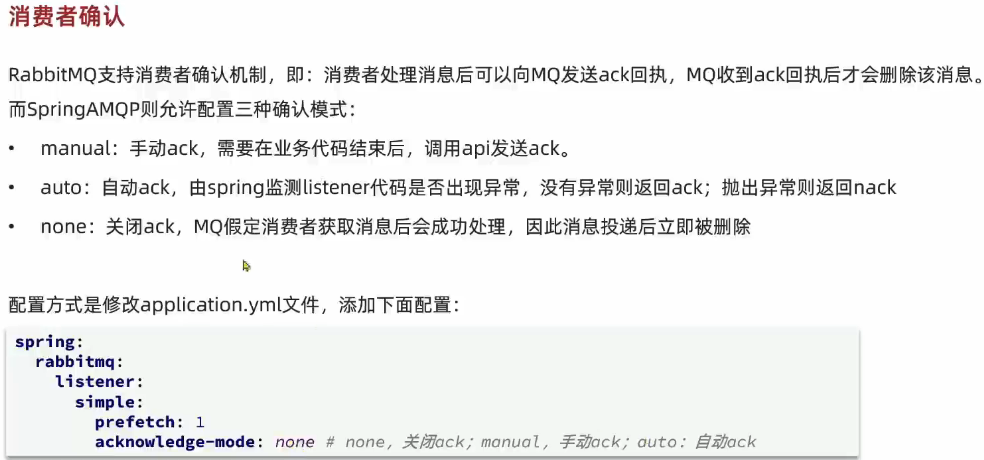
1.4. 消费失败重试机制⭐️🔴
当消费者出现异常后,消息会不断 requeue(重入队)到队列,再重新发送给消费者,然后再次异常,再次 requeue,无限循环,导致 mq 的消息处理飙升,带来不必要的压力
1.4.1. 本地重试
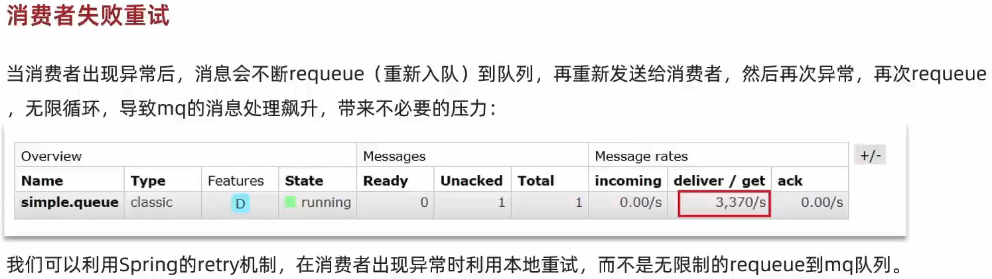

结论:
- 开启本地重试时,消息处理过程中抛出异常,不会 requeue 到队列,而是在消费者本地重试
- 重试达到最大次数后,Spring 会返回 ack,消息会被丢弃
1.4.2. 失败策略

在之前的测试中,达到最大重试次数后,消息会被丢弃,这是由 Spring 内部机制决定的。
在开启重试模式后,重试次数耗尽,如果消息依然失败,则需要有 MessageRecovery 接口来处理,它包含三种不同的实现:
- RejectAndDontRequeueRecoverer:重试耗尽后,直接 reject,丢弃消息。==默认就是这种方式==
- ImmediateRequeueMessageRecoverer:重试耗尽后,返回 nack,消息重新入队
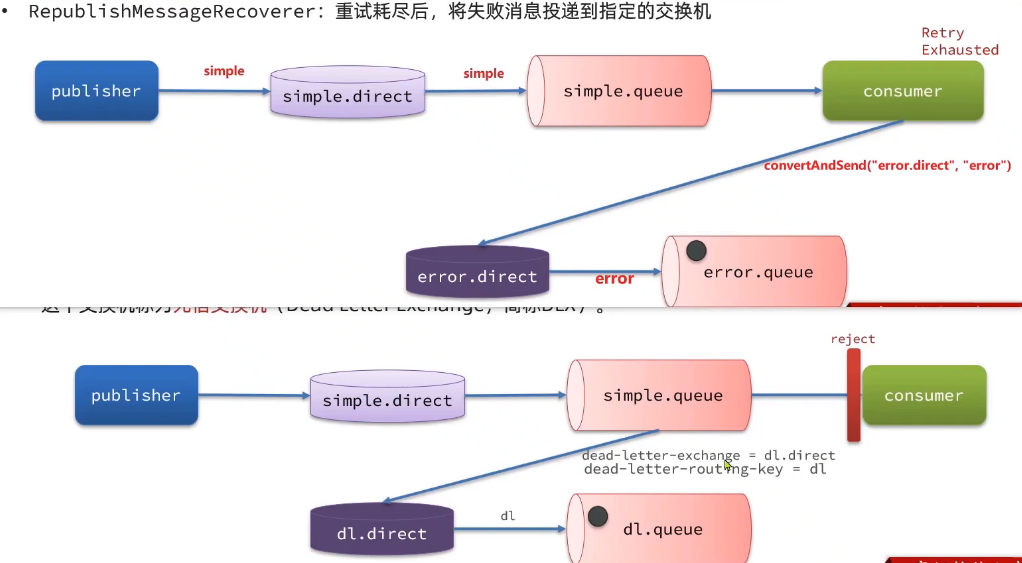
- RepublishMessageRecoverer:重试耗尽后,将失败消息投递到指定的交换机
比较优雅的一种处理方案是 RepublishMessageRecoverer,失败后将消息投递到一个指定的,专门存放异常消息的队列,后续由人工集中处理。
兜底方案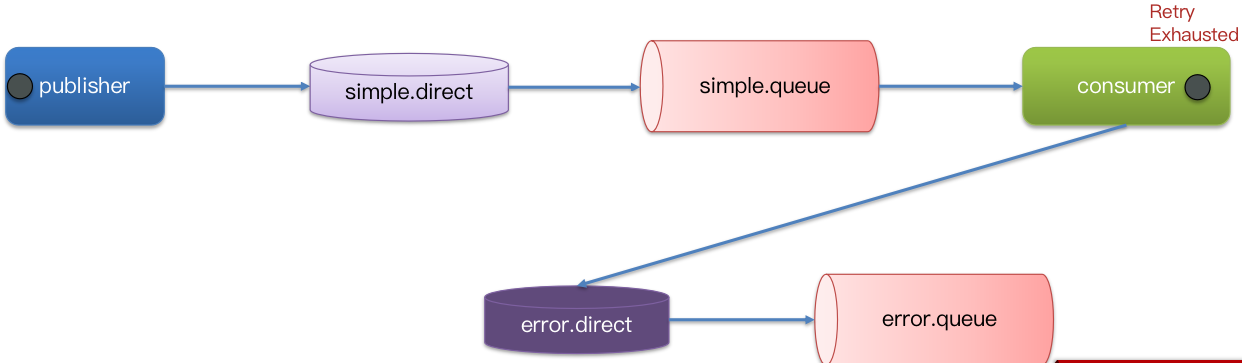
1.5. 如何确保 RabbitMQ 消息的可靠性⭐️🔴
❕ ^yw0uls
❕ ^g43mqv
- 开启==生产者确认机制==,确保生产者的消息能到达队列
- 开启==持久化==功能,确保消息未消费前在队列中不会丢失
- 开启==消费者确认机制为 auto==,由 spring 确认消息处理成功后完成 ack
- 开启==消费者失败重试机制==,并设置 MessageRecoverer,多次重试失败后将消息投递到异常交换机,交由人工处理
1.5.1. 详细说明
[[pages/002-schdule/001-Arch/001-Subject/005-分布式专题/黑马-面试题/讲义/微服务常见面试题#^fzknz2]]
2. 死信交换机
2.1. 什么是死信
当一个队列中的消息满足下列情况之一时,可以成为死信(dead letter):
- 消费者使用 basic.reject 或 basic.nack 声明消费失败,并且消息的 requeue 参数设置为 false
- 消息是一个过期消息,超时无人消费
- 要投递的队列消息满了,无法投递
2.2. 死信交换机
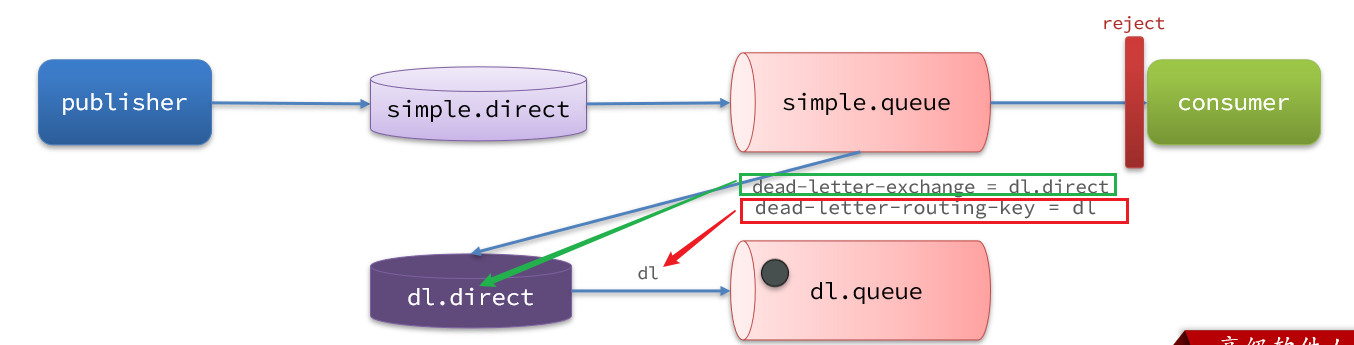
如果这个包含死信的队列配置了 dead-letter-exchange 属性,指定了一个交换机,那么队列中的死信就会投递到这个交换机中,而这个交换机称为 死信交换机(Dead Letter Exchange,检查 DLX)。
如图,一个消息被消费者拒绝了,变成了死信:
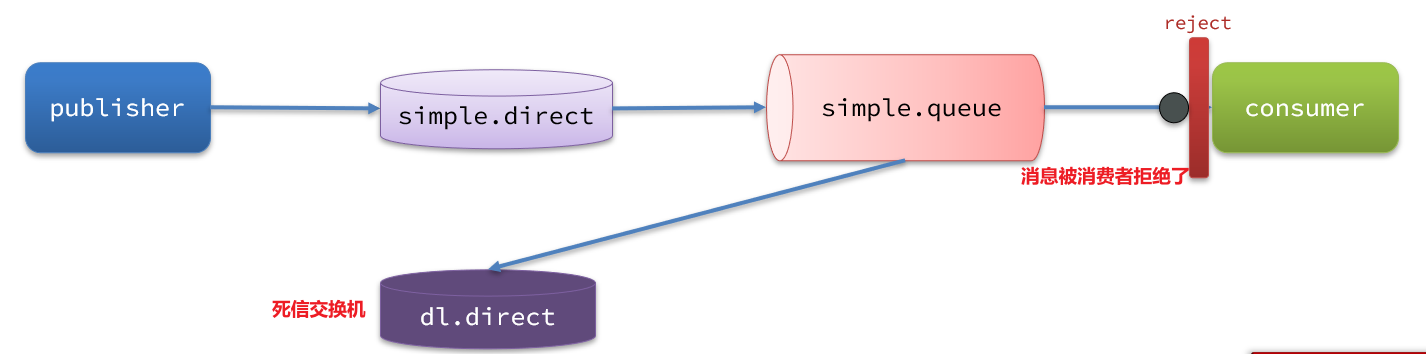
因为 simple.queue 绑定了死信交换机 dl.direct,因此死信会投递给这个交换机:
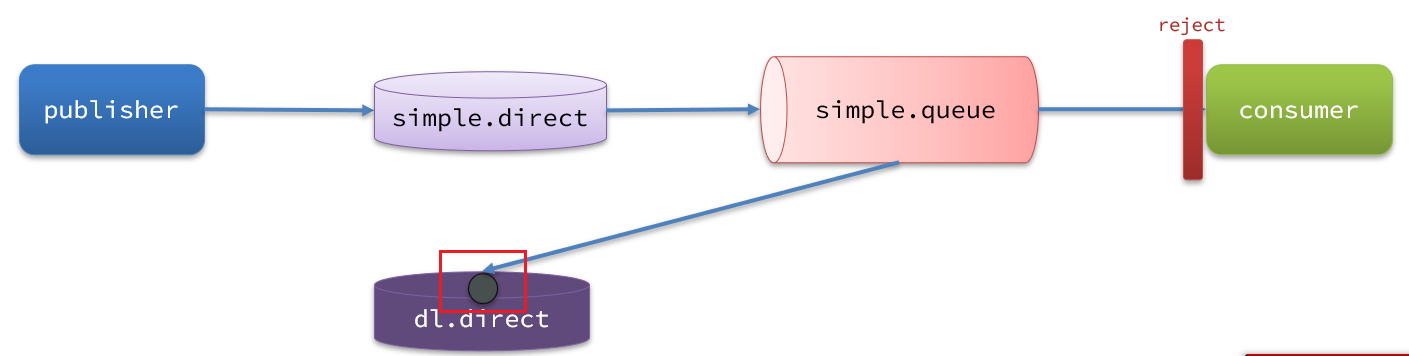
如果这个死信交换机也绑定了一个队列,则消息最终会进入这个存放死信的队列:
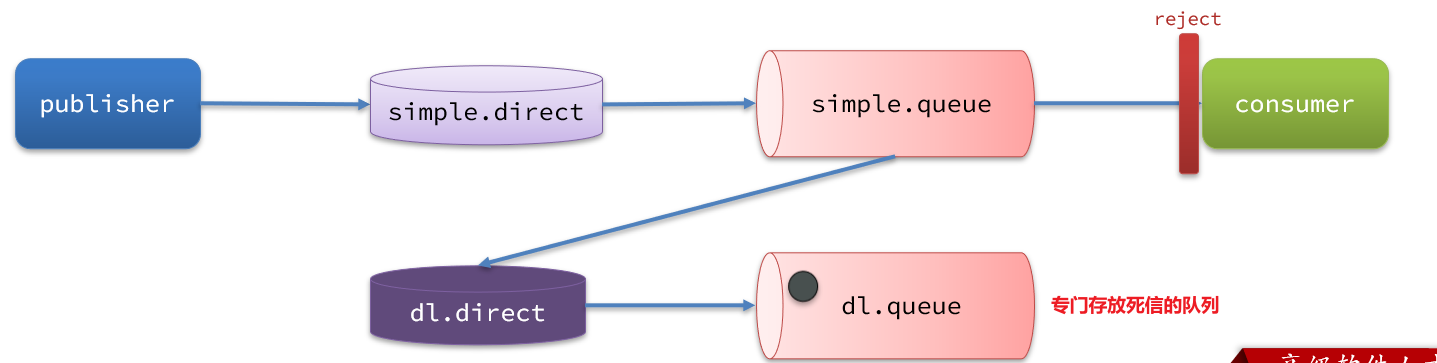
另外,队列将死信投递给死信交换机时,必须知道两个信息:
- 死信交换机名称:
dead-letter-exchange - 死信交换机与死信队列绑定的 RoutingKey:
dead-letter-routing-key
这样才能确保投递的消息能到达死信交换机,并且正确的路由到死信队列。
2.3. 默认兜底方案与死信队列区别
在失败重试策略中,默认的 RejectAndDontRequeueRecoverer 会在本地重试次数耗尽后,发送 reject 给 RabbitMQ,消息变成死信,被丢弃。
2.4. 总结
什么样的消息会成为死信?
❕ ^auuhua
- 消息被消费者 reject 或者返回 nack
- 消息超时未消费
- 队列满了
死信交换机的使用场景是什么?
在失败重试策略中,默认的 RejectAndDontRequeueRecoverer 会在本地重试次数耗尽后,发送 reject 给 RabbitMQ,消息变成死信,被丢弃。
我们可以给 simple.queue 添加一个死信交换机,给死信交换机绑定一个队列。这样消息变成死信后也不会丢弃,而是最终投递到死信交换机,路由到与死信交换机绑定的队列。
- 如果队列绑定了死信交换机,死信会投递到死信交换机;
- 可以利用死信交换机收集所有消费者处理失败的消息(死信),交由人工处理,进一步提高消息队列的可靠性。
3. 延时队列
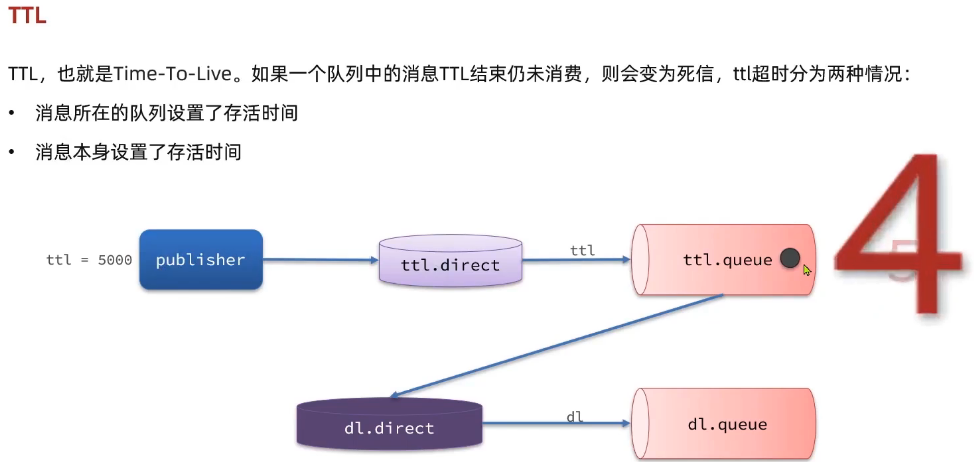
3.1. TTL
一个队列中的消息如果超时未消费,则会变为死信,超时分为两种情况:
- 消息所在的队列设置了超时时间
- 消息本身设置了超时时间
3.2. 延迟队列⭐️🔴
利用 TTL 结合死信交换机,我们实现了消息发出后,消费者延迟收到消息的效果。这种消息模式就称为延迟队列(Delay Queue)模式。
延迟队列的使用场景包括:
- 延迟发送短信
- 用户下单,如果用户在 15 分钟内未支付,则自动取消
- 预约工作会议,20 分钟后自动通知所有参会人员
因为延迟队列的需求非常多,所以 RabbitMQ 的官方也推出了一个插件,原生支持延迟队列效果。这个插件就是 DelayExchange 插件。参考 RabbitMQ 的插件列表页面:https://www.rabbitmq.com/community-plugins.html
4. 惰性队列
4.1. 消息堆积问题
❕ ^4y1a0a
当生产者发送消息的速度超过了消费者处理消息的速度,就会导致队列中的消息堆积,直到队列存储消息达到上限。之后发送的消息就会成为死信,可能会被丢弃,这就是消息堆积问题。
解决消息堆积有两种思路:
- 增加更多消费者,提高消费速度。也就是我们之前说的 work queue 模式
- 扩大队列容积,提高堆积上限
要提升队列容积,把消息保存在内存中显然是不行的。
4.2. 惰性队列
❕ ^k34tgi
从 RabbitMQ 的 3.6.0 版本开始,就增加了 Lazy Queues 的概念,也就是惰性队列。惰性队列的特征如下:
- 接收到消息后直接存入磁盘而非内存
- 消费者要消费消息时才会从磁盘中读取并加载到内存
- 支持数百万条的消息存储
消息堆积问题的解决方案?
- 队列上绑定多个消费者,提高消费速度
- 使用惰性队列,可以在 mq 中保存更多消息
惰性队列的优点有哪些?
- 基于磁盘存储,消息上限高
- 没有间歇性的 page-out,性能比较稳定
惰性队列的缺点有哪些?
- 基于磁盘存储,消息时效性会降低
- 性能受限于磁盘的 IO
5. 高可用方案
❕ ^g8fwqy
5.1. 普通集群
RabbitMQ 提供了两种集群模式: 普通集群模式 镜像集群模式 先来看普通集群 这种集群模式下,各个节点只同步元数据,不同步队列中的消息。 其中元数据包含队列的名称、交换机名称及属性、交换机与队列的绑定关系等。 当我们发送消息和消费消息的时候,不管请求发送到 RabbitMQ 集群的哪个节点。 最终都会通过元数据定位到队列所在的节点去存储以及拉取数据。 很显然,这种集群方式并不能保证 Queue 的高可用,因为一旦 Queue 所在的节 点挂了,那么这个 Queue 的消息就没办法访问了。 它的好处是通过多个节点分担了流量的压力,提升了消息的吞吐能力。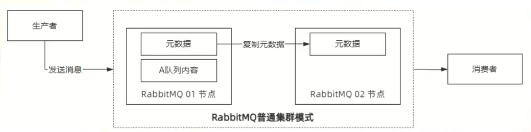
5.2. 镜像集群
它和普通集群的区别在于,镜像集群中 Queue 的数据会在 RabbitMQ 集群的每个节点存储一份。 一旦任意一个节点发生故障,其他节点仍然可以继续提供服务。 所以这种集群模式实现了真正意义上的高可用。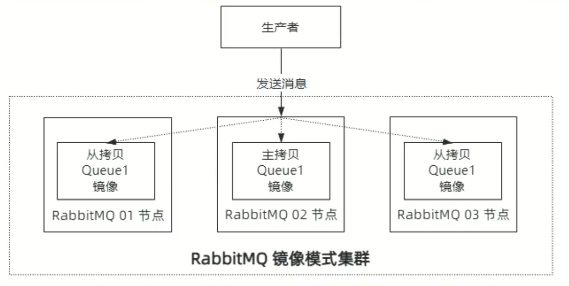
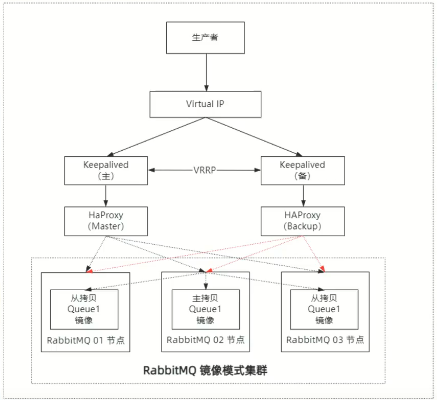
最后,在镜像集群的模式下,我们可以通过 Keepalived+HAProxy 来实现 RabbitMQ 集群的负载均衡。其中: HAProxy 是一个能支持四层和七层的负载均衡器,可以实现对 RabbitMQ 集群的负载均衡同时为了避免 HAProxy 的单点故障,可以再增加 Keepalived 实现 HAProxy 的主备,如果 HAProxy 主节点出现故障那么备份节点就会接管主节点提供服务。 Keepalived 提供了一个虚拟 IP,业务只需要连接到虚拟 IP 即可。
6. 面试题
6.1. RabbitMQ 实现高可用
6.2. RabbitMQ 实现可靠消息传递
分布式专题-MQ-RabbitMQ-1、基本原理6.3. RabbitMQ 的消息如何实现路由
https://www.bilibili.com/video/BV1uG411x7r4/?spm_id_from=333.788&vd_source=c5b2d0d7bc377c0c35dbc251d95cf204
RabbitMQ 是一个基于高级消息队列协议 AMQP(Advanced Message Queuing Protocol) 协议实现的分布式消息中间件。AMQP 的具体工作机制是,生产者把消息发送到 RabbitMQ Broker 上的 Exchange 交换机上。 Exchange 交换机把收到的消息根据路由规则发给绑定的队列(Queue)。最后再把消息投递给订阅了这个队列的消费者,从而完成消息的异步通讯。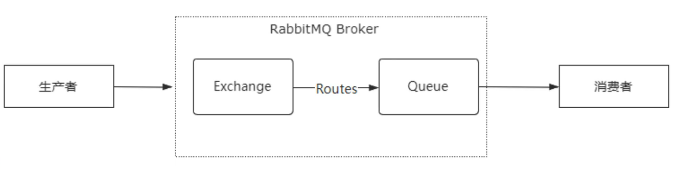
其中,Exchange 是一个消息交换机,它里面定义了消息路由的规则,也就是这个消息路由到那个队列。 然后 Queue 表示消息的载体,每个消息可以根据路由规则路由到一个或者多个队列里面。 而关于消息的路由机制,核心的组件是 Exchange。 它负责接收生产者的消息然后把消息路由到消息队列,而消息的路由规则由 ExchangeType 和 Binding 决定。 Binding 表示建立 Queue 和 Exchange 之间的绑定关系,每一个绑定关系会存在一个 BindingKey。 通过这种方式相当于在 Exchange 中建立了一个路由关系表。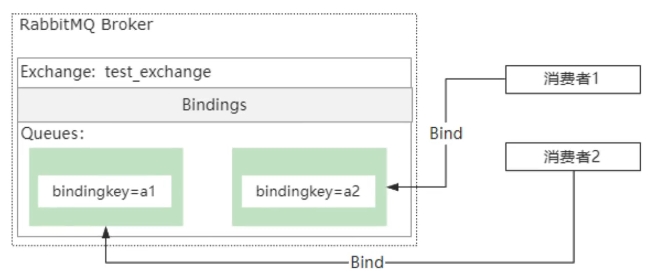
生产者发送消息的时候,需要声明一个 routingKey(路由键),Exchange 拿到 routingKey 之后,根据 RoutingKey 和路由表里面的 BindingKey 进行匹配,而匹配的规则是通过 ExchangeType 来决定的。
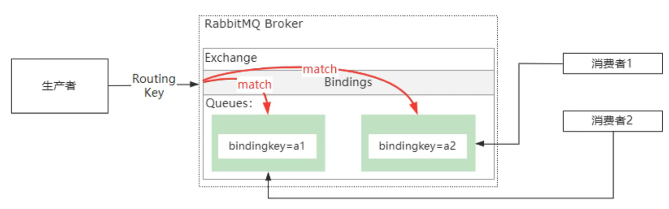
在 RabbitMQ 中,有三种类型的 Exchange:direct ,fanout 和 topic。 direct: 完整匹配方式,也就是 Routing key 和 Binding Key 完全一致,相当于点对点的发送。 fanout: 广播机制,这种方式不会基于 Routing key 来匹配,而是把消息广播给绑定到当前 Exchange 上的所有队列上。 topic: 正则表达式匹配,根据 Routing Key 使用正则表达式进行匹配,符合匹配规则的 Queue 都会收到这个消息
7. 实战经验
8. 参考与感谢
8.1. 视频
8.2. 资料
/Users/taylor/Nutstore Files/Obsidian_data/pages/002-schdule/001-Arch/001-Subject/002- 框架源码专题/001-MQ/黑马 MQ 讲义/day05-MQ 高级/讲义/RabbitMQ- 高级篇.md
 微信
微信 支付宝
支付宝