
框架源码专题-MySQL-4、锁
1. 行锁、记录锁、临键锁、间隙锁
❕ ^vafwau
记录锁、临键锁、间隙锁,都是 Mysql 里面 InnoDB 引擎下解决事务隔离性的一系列排他锁。
行级锁的种类主要有三类:
- Record Lock,记录锁,也就是仅仅把一条记录锁上;
- Gap Lock,间隙锁,锁定一个范围,但是不包含记录本身;
- Next-Key Lock:Record Lock + Gap Lock 的组合,锁定一个范围,并且锁定记录本身。
1.1. 查看命令
有什么命令可以分析加了什么锁
1 | |
这条语句,查看事务执行 SQL 过程中加了什么锁。
1.2. 记录锁 - 主键或者唯一索引
当我们针对主键或者唯一索引加锁的时候,Mysql 默认会对查询的这一行数据加行锁,避免其他事务对这一行数据进行修改。
锁住的是一条记录。而且记录锁是有 S 锁和 X 锁之分的:
- 当一个事务对一条记录加了 S 型记录锁后,其他事务也可以继续对该记录加 S 型记录锁(S 型与 S 锁兼容),但是不可以对该记录加 X 型记录锁(S 型与 X 锁不兼容);
- 当一个事务对一条记录加了 X 型记录锁后,其他事务既不可以对该记录加 S 型记录锁(S 型与 X 锁不兼容),也不可以对该记录加 X 型记录锁(X 型与 X 锁不兼容)。
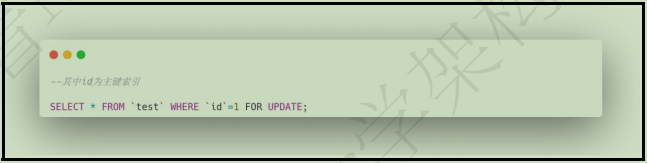
1.3. 间隙锁 - 普通索引或者唯一索引 - 左右开区间
顾名思义,就是锁定一个索引区间。 在普通索引或者唯一索引列上,由于索引是基于 B+ 树的结构存储,所以默认会存在一个索引区间。 而间隙锁,就是某个事物对索引列加锁的时候,默认锁定对应索引的左右开区间范围。
基于主键的插入操作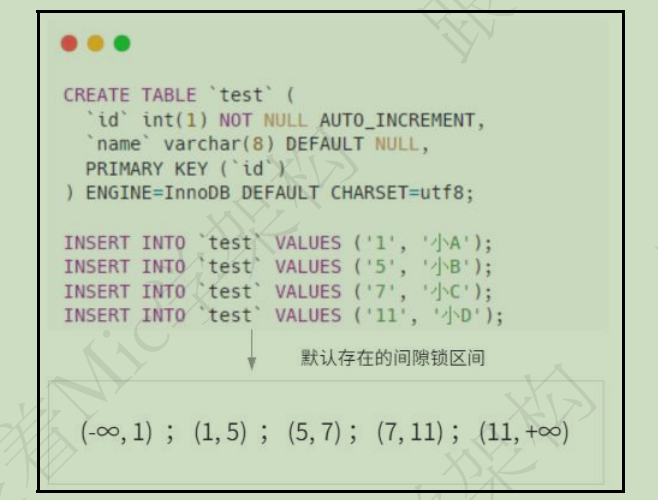
1.4. 临键锁 - 非唯一索引 - 左开右闭
它相当于行锁 + 间隙锁的组合,也就是它的锁定范围既包含了索引记录,也包含了索引区间,它会锁定一个左开右闭区间的数据范围。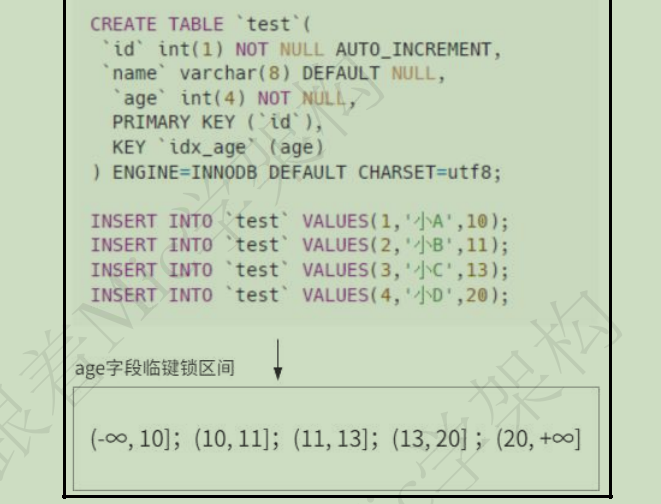
假设我们使用非唯一索引列进行查询的时候,默认会加一个临键锁,锁定一个左开右闭区间的范围。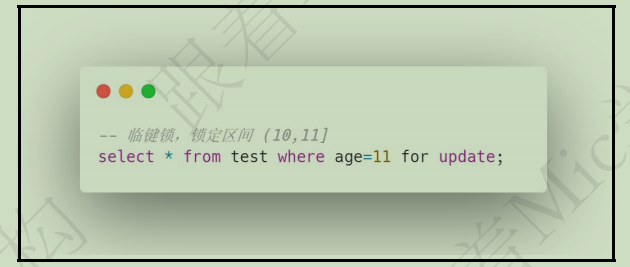
非唯一索引和主键索引的范围查询的加锁也有所不同,不同之处在于 非唯一索引范围查询,索引的 next-key lock 不会有退化为间隙锁和记录锁的情况,也就是非唯一索引进行范围查询时,对二级索引记录加锁都是加 next-key 锁。
1.5. 加锁规则
1.5.1. 唯一索引等值查询
当我们用唯一索引进行等值查询的时候,查询的记录存不存在,加锁的规则也会不同:
- 当查询的记录是「存在」的,在索引树上定位到这一条记录后,将该记录的索引中的 next-key lock 会 退化成「记录锁」。
- 当查询的记录是「不存在」的,在索引树找到第一条大于该查询记录的记录后,将该记录的索引中的 next-key lock 会 退化成「间隙锁」。左右开区间

1.5.2. 唯一索引范围查询
范围查询和等值查询的加锁规则是不同的。
当唯一索引进行范围查询时,会对每一个扫描到的索引加 next-key 锁,然后如果遇到某些情况,会退化成记录锁或者间隙锁
1.5.3. 非唯一索引等值查询
当我们用非唯一索引进行等值查询的时候,因为存在两个索引,一个是主键索引,一个是非唯一索引(二级索引),所以在加锁时,同时会对这两个索引都加锁,但是对主键索引加锁的时候,只有满足查询条件的记录才会对它们的主键索引加锁。

35丨记一次线上SQL死锁事故:如何避免死锁 例子中描述不对,待验证
- 🚩 - 待验证非唯一索引的等值查询的加锁逻辑 - 🏡 2023-04-12 16:14
#todo
1.5.4. 非唯一索引范围查询
非唯一索引和主键索引的范围查询的加锁也有所不同,不同之处在于 非唯一索引范围查询,索引的 next-key lock 不会有退化为间隙锁和记录锁的情况,也就是非唯一索引进行范围查询时,对二级索引记录加锁都是加 next-key 锁。
1.5.5. 没有加索引的查询 - 全表扫描
前面的案例,我们的查询语句都有使用索引查询,也就是查询记录的时候,是通过索引扫描的方式查询的,然后对扫描出来的记录进行加锁。
如果锁定读查询语句,没有使用索引列作为查询条件,或者查询语句没有走索引查询,导致扫描是全表扫描。那么,每一条记录的索引上都会加 next-key 锁,这样就相当于锁住的全表,这时如果其他事务对该表进行增、删、改操作的时候,都会被阻塞。
不只是锁定读查询语句不加索引才会导致这种情况,update 和 delete 语句如果查询条件不加索引,那么由于扫描的方式是全表扫描,于是就会对每一条记录的索引上都会加 next-key 锁,这样就相当于锁住的全表。
因此,在线上在执行 update、delete、select … for update 等具有加锁性质的语句,一定要检查语句是否走了索引,如果是全表扫描的话,会对每一个索引加 next-key 锁,相当于把整个表锁住了,这是挺严重的问题。
1.6. 总结⭐️🔴
❕ ^me3j71
这次我以 MySQL 8.0.26 版本,在可重复读隔离级别之下,做了几个实验,让大家了解了唯一索引和非唯一索引的行级锁的加锁规则。
1.6.1. 唯一索引等值查询
- 当查询的记录是「存在」的,在索引树上定位到这一条记录后,将该记录的索引中的 next-key lock 会 退化成「记录锁」。
- 当查询的记录是「不存在」的,在索引树找到第一条大于该查询记录的记录后,将该记录的索引中的 next-key lock 会 退化成「间隙锁」。左右开区间
1.6.2. 非唯一索引等值查询
- 当查询的记录「存在」时,由于不是唯一索引,所以肯定存在索引值相同的记录,于是非唯一索引等值查询的过程是一个扫描的过程,直到扫描到第一个不符合条件的二级索引记录就停止扫描,然后 在扫描的过程中,对扫描到的二级索引记录加的是 next-key 锁,而对于第一个不符合条件的二级索引记录,该二级索引的 next-key 锁会退化成间隙锁。同时,在符合查询条件的记录的主键索引上加记录锁

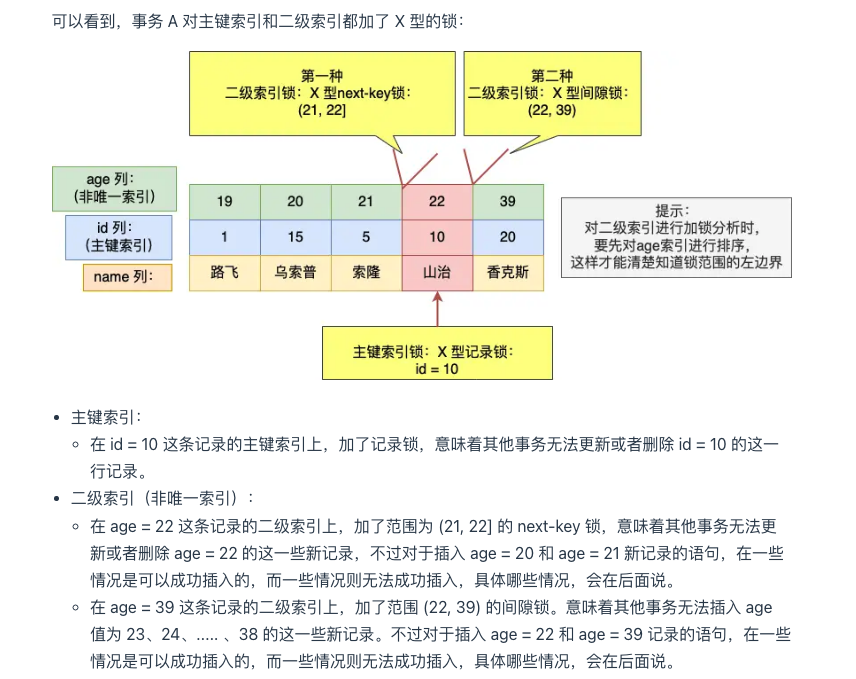
当查询的记录「不存在」时,扫描到第一条不符合条件的二级索引记录,该二级索引的 next-key 锁会退化成间隙锁。因为不存在满足查询条件的记录,所以不会对主键索引加锁。
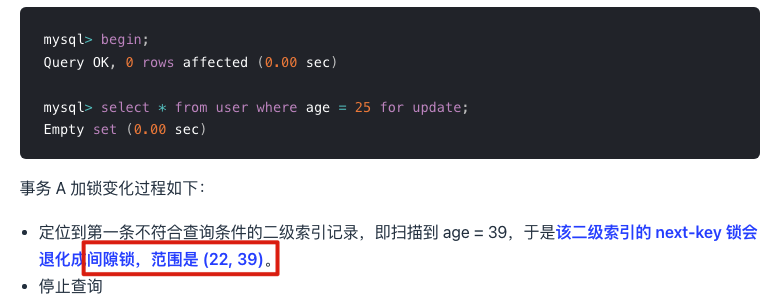
1.6.3. 唯一索引和非唯一索引的范围查询的加锁规则
- 唯一索引在满足一些条件的时候,索引的 next-key lock 退化为间隙锁或者记录锁。
- 非唯一索引范围查询,索引的 next-key lock 不会退化为间隙锁和记录锁。
其实理解 MySQL 为什么要这样加锁,主要要以避免幻读角度去分析,这样就很容易理解这些加锁的规则了。
1.6.4. 具有加锁性质的语句
还有一件很重要的事情,在线上在执行 update、delete、select … for update 等具有加锁性质的语句,一定要检查语句是否走了索引,如果是全表扫描的话,会对每一个索引加 next-key 锁,相当于把整个表锁住了,这是挺严重的问题。
所以总的来说,行锁、临键锁、间隙锁只是表示锁定数据的范围,最终目的是为了解决幻读的问题。而临键锁相当于行锁 + 间隙锁,因此当我们使用非唯一索引进行精准匹配的时候,会默认加临键锁,因为它需要锁定匹配的这一行数据,还需要锁定这一行数据对应的左开右闭区间。
因此在实际应用中,尽可能使用唯一索引或者主键索引进行查询,避免大面积的 锁定造成性能影响。
2. 意向锁⭐️🔴
https://juejin.cn/post/6844903666332368909
2.1. 是一种表锁
InnoDB 支持 多粒度锁(multiple granularity locking),它允许 行级锁 与 表级锁 共存,而 意向锁 就是其中的一种 不与行级锁冲突表级锁。
2.2. 类型:IS、IX
意向锁分为两种:
意向共享锁(intention shared lock, IS):事务有意向对表中的某些行加 共享锁(S 锁)
1
2-- 事务要获取某些行的 S 锁,必须先获得表的 IS 锁。
SELECT column FROM table ... LOCK IN SHARE MODE;意向排他锁(intention exclusive lock, IX):事务有意向对表中的某些行加 排他锁(X 锁)
1
2-- 事务要获取某些行的 X 锁,必须先获得表的 IX 锁。
SELECT column FROM table ... FOR UPDATE;
2.3. 谁来维护 -InooDB 自动加
意向锁是有数据引擎自己维护的,用户无法手动操作意向锁。用户加锁时,InooDB 在给数据行加共享 / 排他锁之前,会先获取该数据行所在数据表的对应意向锁。
2.4. 特性 - 除所有行级锁及共享表锁,其他都互斥
- InnoDB 支持
多粒度锁,特定场景下,行级锁可以与表级锁共存。 - 意向锁之间互不排斥,但除了 IS 与 S 兼容外,
意向锁会与 共享锁 / 排他锁 互斥 - IX、IS 是表级锁,不会和行级的 X、S 锁发生冲突。只会和表级的 X、S 发生冲突。
- 意向锁在保证并发性的前提下,实现了
行锁和表锁共存且满足事务隔离性的要求。
2.5. 作用 - 锁粗化提高互斥判断性能
事务 A 获取了某一行的排他锁,并未提交:
1 | |
事务 B 想要获取 users 表的表锁:
1 | |
因为共享锁与排他锁 互斥,所以事务 B 在试图对 users 表加共享锁的时候,必须保证:
- 当前没有其他事务持有 users 表的排他锁。
- 当前没有其他事务持有 users 表中任意一行的排他锁 。
为了检测是否满足第二个条件,事务 B 必须在确保 users 表不存在任何排他锁的前提下,去检测表中的每一行是否存在排他锁。很明显这是一个效率很差的做法!
但是有了 意向锁 之后,情况就不一样了:
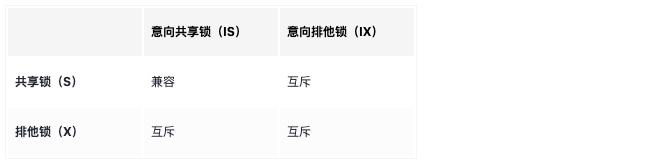
意向锁之间是互相兼容的
虽然意向锁和自家兄弟互相兼容,但是它会与普通的 排他 / 共享锁 互斥:
注意:
这里的排他 / 共享锁指的都是表锁!!!
意向锁不会与行级的共享 / 排他锁互斥!!!
现在我们回到刚才 users 表的例子:事务 A 获取了某一行的排他锁,并未提交:
1 | |
此时 users 表存在两把锁:users 表上的 意向排他锁 与 id 为 6 的数据行上的 排他锁。
事务 B 想要获取 users 表的共享锁:
1 | |
此时 事务 B 检测事务 A 持有 users 表的 意向排他锁,就可以得知 事务 A 必然持有该表中某些数据行的 排他锁,那么 事务 B 对 users 表的加锁请求就会被排斥(阻塞),而无需去检测表中的每一行数据是否存在排他锁。
3. 插入意向锁
https://juejin.cn/post/6844903666856493064#comment
总结一下:
- 插入意向锁虽然名字中有意向二字,但实际上是一个特殊的间隙锁。
- 插入意向锁之间不互斥。
- 插入意向锁和排他锁之间互斥。
4. SQL 死锁
❕ ^q4zhga
4.1. 插入意向锁 - 死锁分析
https://toutiao.io/posts/e3xkkv/preview


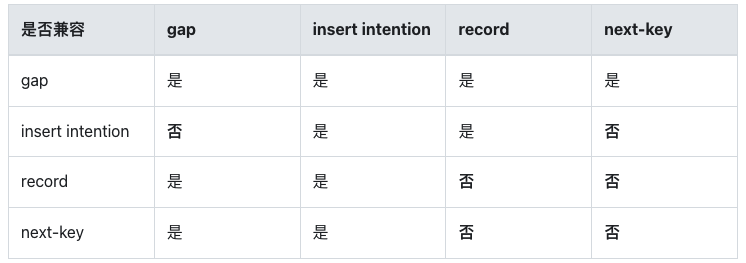
- 不带插入意向锁标记的间隙锁(不包括 next 锁)不受任何锁阻挡
- 间隙锁(不包括 next 锁)只阻挡插入意向锁
- 行锁不阻挡间隙锁(不包括 next 锁)
- 插入意向锁不阻挡任何锁(由于第一个 case 已经对间隙锁做过特殊处理,与第一条结论不冲突)
4.2. 死锁案例⭐️🔴
4.2.1. 同一张表插入语句遇到间隙锁
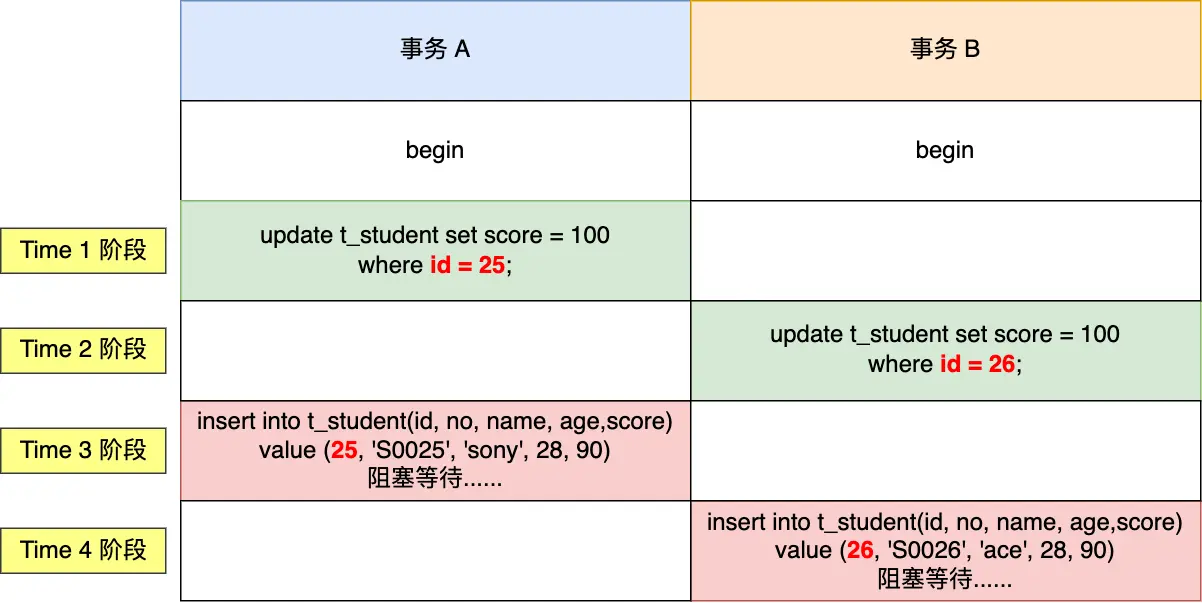
两个事务即使生成的间隙锁的范围是一样的,也不会发生冲突,因为间隙锁目的是为了防止其他事务插入数据,因此间隙锁与间隙锁之间是相互兼容的。
在执行插入语句时,如果插入的记录在其他事务持有间隙锁范围内,插入语句就会被阻塞,因为插入语句在碰到间隙锁时,会生成一个插入意向锁,然后插入意向锁和间隙锁之间是互斥的关系。
如果两个事务分别向对方持有的间隙锁范围内插入一条记录,而插入操作为了获取到插入意向锁,都在等待对方事务的间隙锁释放,于是就造成了循环等待,满足了死锁的四个条件:互斥、占有且等待、不可强占用、循环等待,因此发生了死锁。
4.2.2. 幂等性校验的一张表经常出现死锁异常
1 | |
4.2.3. 其他案例
https://juejin.cn/post/7160649681578491940
4.3. 如何定位死锁
1 | |
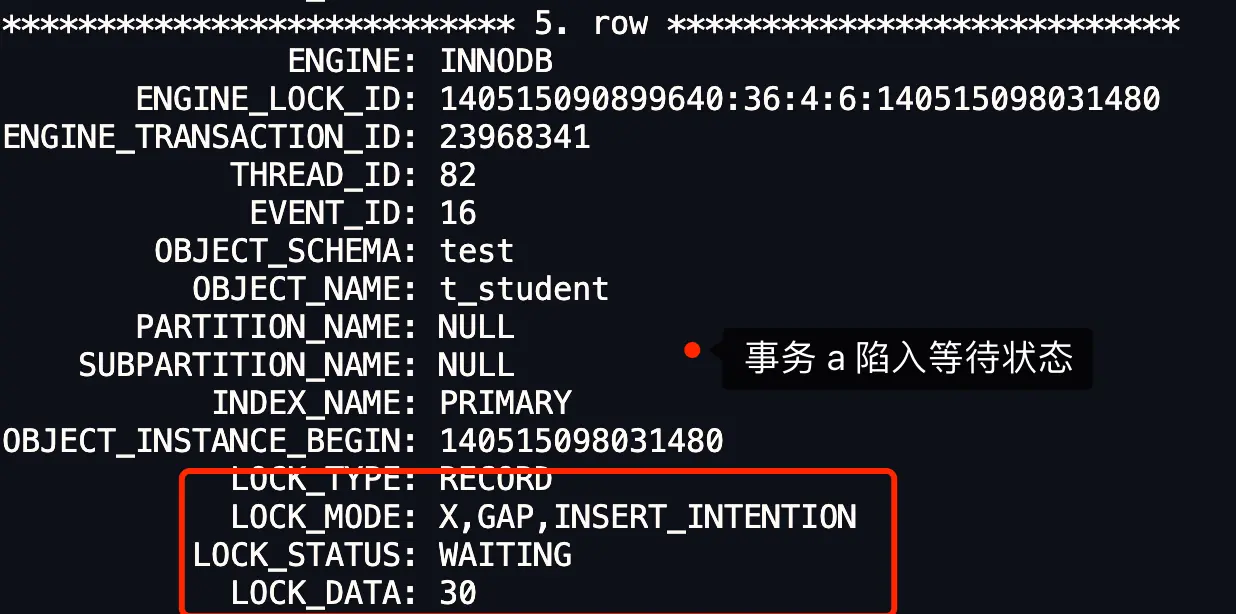
可以看到一直是 waiting 状态
4.4. 防止死锁⭐️🔴
❕ ^thujzj
整体上:在允许幻读和不可重复读的情况下,尽量使用 RC 事务隔离级别,可以避免 gap lock 导致的死锁问题;
更新顺序:
记录:
在编程中尽量按照固定的顺序来处理数据库记录,假设有两个更新操作,分别更新两条相同的记录,但更新顺序不一样,有可能导致死锁;
表:
用户 A 访问表 A(锁住了表 A),然后又访问表 B;另一个用户 B 访问表 B(锁住了表 B),然后企图访问表 A;这时用户 A 由于用户 B 已经锁住表 B,它必须等待用户 B 释放表 B 才能继续,同样用户 B 要等用户 A 释放表 A 才能继续,这就死锁就产生了。
用户 A–》A 表(表锁)–》B 表(表锁)
用户 B–》B 表(表锁)–》A 表(表锁)
- 更新表时,尽量使用主键更新;
- 避免长事务,尽量将长事务拆解,可以降低与其它事务发生冲突的概率;
- 设置锁等待超时参数,我们可以通过
innodb_lock_wait_timeout设置合理的等待超时阈值,特别是在一些高并发的业务中,我们可以尽量将该值设置得小一些,避免大量事务等待,占用系统资源,造成严重的性能开销。 - MySQL 默认开启了死锁检测机制,当检测到死锁后会选择一个最小 (锁定资源最少得事务) 的事务进行回滚。
innodb_deadlock_detect = on打开死锁检测
4.5. 解除死锁
1.查询是否锁表
1 | |
2.查询进程(如果您有 SUPER 权限,您可以看到所有线程。否则,您只能看到您自己的线程)
1 | |
3.杀死进程 id(就是上面命令的 id 列)
1 | |
其它关于查看死锁的命令:
1:查看当前的事务
SELECT * FROM INFORMATION_SCHEMA.INNODB_TRX;2:查看当前锁定的事务
SELECT * FROM INFORMATION_SCHEMA.INNODB_LOCKS;
3:查看当前等锁的事务
SELECT * FROM INFORMATION_SCHEMA.INNODB_LOCK_WAITS;
死锁解决
方案如下几种选择:
- 不采用事务包装这部分逻辑,本文实际业务场景中可以不需要事务,所以直接取消事务包装即可,采用 insert ON DUPLICATE KEY UPDATE 的方式
- 调整事务隔离级别为 read commit,RC 级别不会产生 gap lock
- 利用分布式锁
附:排查过程
查看死锁日志,注意这里并不会包含整个事务的相关 sql,仅仅会把等待锁的 SQL 打印出来,死锁日志内容含义参考 : http://blog.itpub.net/22664653/viewspace-2145133/
根据服务异常 log 定位到具体事务执行代码,找出该事务相关的 sql
根据积累的经验知识分析加锁、锁等待情况,找出死锁原因
https://blog.51cto.com/u_14286115/3906999
4.6. 线程死锁
并发基础-9、Java各种锁5. InnoDB 的行锁优化
InnoDB 存储引擎由于实现了行级锁定,虽然在锁定机制的实现方面带来了性能损耗可能比表锁会更高一些,但是在整体并发处理能力方面要远远高于 MyISAM 的表锁的。当系统并发量较高的时候,InnoDB 的整体性能和 MyISAM 相比就会有比较明显的优势。
但是,InnoDB 的行级锁同样也有其脆弱的一面,当我们使用不当的时候,可能会让 InnoDB 的整体性能表现不仅不能比 MyISAM 高,甚至可能会更差。
优化建议:
- 尽可能让所有数据检索都能通过索引来完成,避免无索引行锁升级为表锁。
- 合理设计索引,尽量缩小锁的范围
- 尽可能减少索引条件,及索引范围,避免间隙锁
- 尽量控制事务大小,减少锁定资源量和时间长度
- 尽可使用低级别事务隔离(但是需要业务层面满足需求)




唯一索引跟主键一样,如果是普通索引,只对查出的记录加锁
可重复读隔离级别,对查出的记录(包括全表查询),加了间隙锁,所以防止了幻读
5.1. 验证 Demo
https://segmentfault.com/a/1190000039876266?utm_source=sf-similar-article
1 | |
1 | |
https://segmentfault.com/a/1190000023869573
1 | |
1 | |
1 | |
6. 实战经验
7. 参考与感谢
7.1. 锁
https://segmentfault.com/a/1190000023869573
7.2. 黑马
7.2.1. 视频
7.2.2. 资料
[[Mysql高级-day03]]
7.3. 小林 coding
https://xiaolincoding.com/mysql/lock/how_to_lock.html#gap-lock
 微信
微信 支付宝
支付宝