
并发编程专题-基础-13、线程池
1. 自定义
1.1. 四种自带线程池
1.1.1. 阻塞队列无界 -fixed-single
1.1.1.1. newFixedThreadPool-nThreads

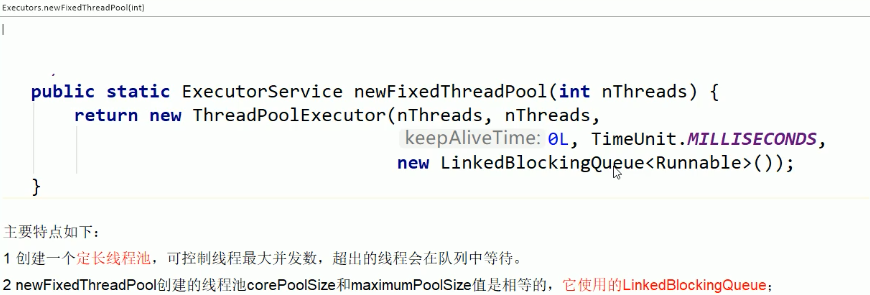
1.1.1.2. newSingleThreadExecutor-1-1

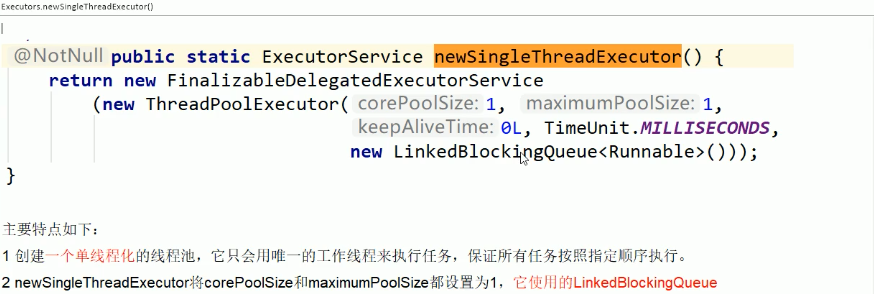
1.1.2. 最大线程数无界 -cached-scheduled
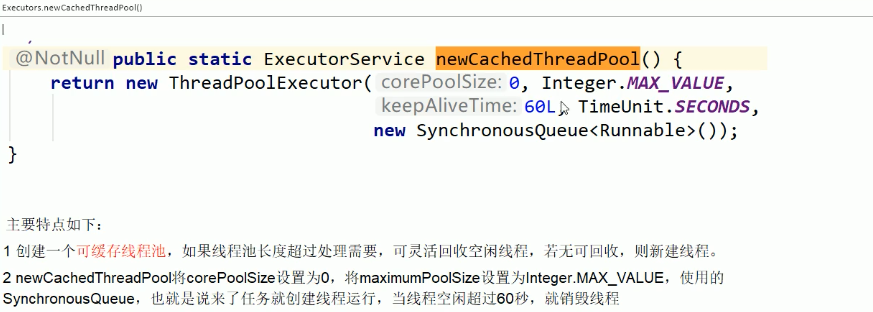
1.1.2.1. newCachedThreadPool

1.1.2.2. newScheduledThreadPool


1.1.3. ForkJoinPool
1.1.3.1. newWorkStealingPool


创建一个拥有多个任务队列的线程池,可以减少连接数,创建当前可用 cpu 数量的线程来并行执行,适用于大耗时的操作,可以并行来执行
使用了一个无限队列来保存需要执行的任务,而线程的数量则是通过构造函数传入,如果没有向构造函数中传入希望的线程数量,那么当前计算机可用的 CPU 数量会被设置为线程数量作为默认值。
newWorkStealingPool 会创建一个含有足够多线程的线程池,来维持相应的并行级别,它会通过工作窃取的方式,使得多核的 CPU 不会闲置,总会有活着的线程让 CPU 去运行。
ForkJoinPool 主要用来使用分治法 (Divide-and-Conquer Algorithm) 来解决问题。ForkJoinPool 的优势在于,可以充分利用多 cpu,多核 cpu 的优势,把一个任务拆分成多个“小任务”分发到不同的 cpu 核心上执行,执行完后再把结果收集到一起返回。典型的应用比如快速排序算法。这里的要点在于,ForkJoinPool 需要使用相对少的线程来处理大量的任务。比如要对 1000 万个数据进行排序,那么会将这个任务分割成两个 500 万的排序任务和一个针对这两组 500 万数据的合并任务。以此类推,对于 500 万的数据也会做出同样的分割处理,到最后会设置一个阈值来规定当数据规模到多少时,停止这样的分割处理。比如,当元素的数量小于 10 时,会停止分割,转而使用插入排序对它们进行排序。
https://www.cnblogs.com/duanxz/p/5056222.html
1.2. 为什么要自定义⭐️🔴

2. 七大参数
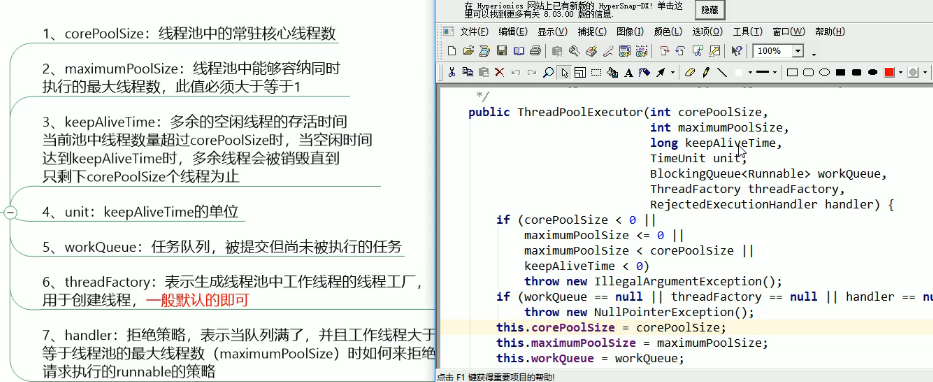
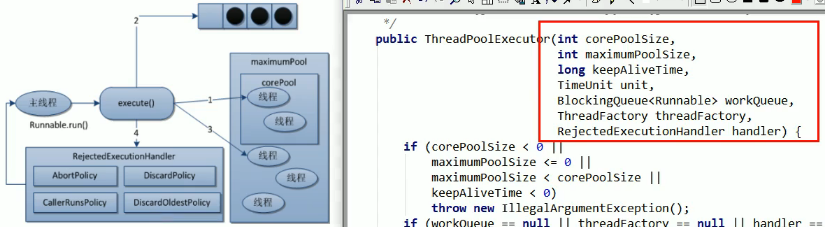
2.1. 阻塞队列
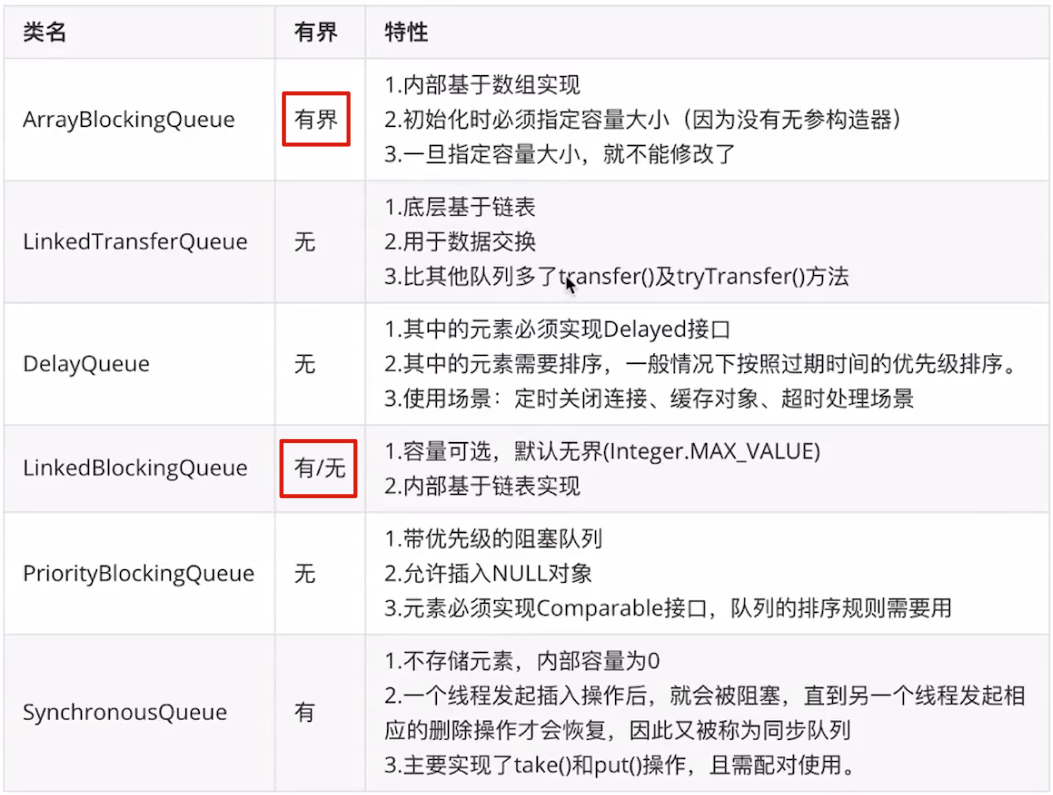

2.2. 拒绝策略

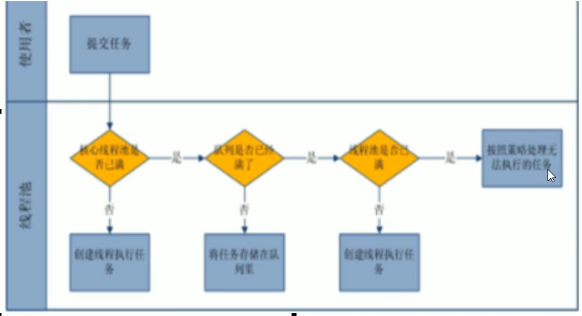
3. 扩容流程

4. 最大线程数配置
[[合理配置线程池的线程数量 - 掘金]]
4.1. CPU 密集型
CPU 密集型也就是计算密集型,常常指算法复杂的程序,需要进行大量的逻辑处理与计算,CPU 在此期间是一直在工作的。
在这种情况下 CPU 的利用率会非常高,我们的最大核心数设置为 CPU 的核心数即可。
这种情况下 CPU 几乎满负荷运行,我们配置的数字在大也没有效果,反而会增大额外的切换开销。
在《Java Concurrency in Practice》中,推荐将 CPU 密集型最大线程数设置为 最大线程数 = CPU 核心数 + 1,这样能发挥最高效率。
核心线程数一般会设置为 **核心线程数 = 最大线程数 * 20%**。
4.2. IO 密集型
IO 密集型是指我们程序更多的工作是在通过磁盘、内存或者是网络读取数据,在 IO 期间我们线程是阻塞的,这期间 CPU 其实也是空闲的,这样我们的操作系统就可以切换其他线程来使用 CPU 资源。
通常在进行接口远程调用,数据库数据获取,缓冲数据获取都属于 IO 操作。
这时我们线程数可以通过以下公式进行计算:最大线程数 = CPU 核心数 / (1 - 阻塞占百分比)。
我们很好理解比如在某个请求中,请求时长为 10 秒,调用 IO 时间为 8 秒,这时我们阻塞占百分比就是 80%,有效利用 CPU 占比就是 20%,假设是八核 CPU,我们线程数就是 8 / (1 - 80%) = 8 / 0.2 = 40 个。
也就是说 我们八核 CPU 在上述情况中,可满负荷运行 40 个线程。这时我们可将最大线程数调整为 40,在系统进行 IO 操作时会去处理其他线程。
4.3. 混合型

4.3.1. 懒人工具
https://www.javacodegeeks.com/2012/03/threading-stories-about-robust-thread.html
4.4. 实际考虑因素
https://tech.meituan.com/2020/04/02/java-pooling-pratice-in-meituan.html
[[线程池大小 + 线程数量到底设置多少? - 腾讯云开发者社区-腾讯云]]
[[如何设置线程池参数?美团给出了一个让面试官虎躯一震的回答。 - why技术 - 博客园]]
5. 实战经验
5.1. 线程池预热
问题一:线程池被创建后里面有线程吗?如果没有的话,你知道有什么方法对线程池进行预热吗?
线程池被创建后如果没有任务过来,里面是不会有线程的。如果需要预热的话可以调用下面的两个方法:
5.1.1. 全部启动
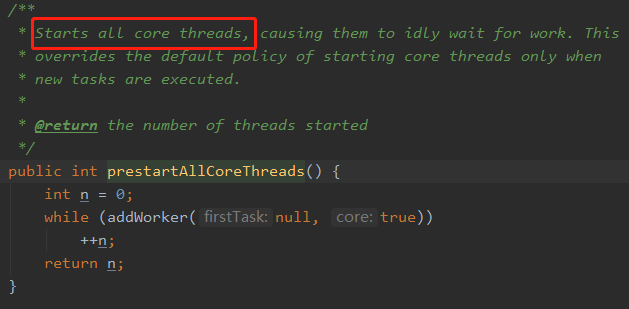
5.1.2. 仅启动一个
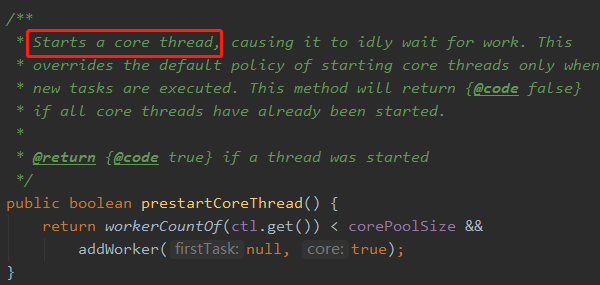
问题二:核心线程数会被回收吗?需要什么设置?
核心线程数默认是不会被回收的,如果需要回收核心线程数,需要调用下面的方法: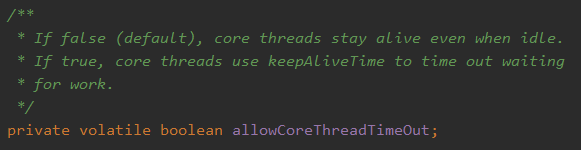
allowCoreThreadTimeOut 该值默认为 false。
5.2. 线程池如何知道一个线程的任务已经执行完成
5.2.1. 线程池内部
在线程池内部,当我们把一个任务丢给线程池去执行,线程池会调度工作线程来执行这个任务的 run 方法,run 方法正常结束,也就意味着任务完成了。所以线程池中的工作线程是通过同步调用任务的 run() 方法并且等待 run 方法返回后,再去统计任务的完成数量。
5.2.2. 线程池外部
5.2.2.1. 轮询线程池的 isTerminated()方法
线程池提供了一个 isTerminated() 方法,可以判断线程池的运行状态,我们可以循环判断 isTerminated() 方法的返回结果来了解线程池的运行状态,一旦线程池的运行状态是 Terminated,意味着线程池中的所有任务都已经执行完了。想要通过这个方法获取状态的前提是,程序中主动调用了线程池的 shutdown() 方法。在实际业务中,一般不会主动去关闭线程池,因此这个方法在实用性和灵活性方面都不是很好。
5.2.2.2. future.get()- 会阻塞
在线程池中,有一个 submit() 方法,它提供了一个 Future 的返回值,我们通过 Future.get() 方法来获得任务的执行结果,当线程池中的任务没执行完之前, future.get() 方法会一直阻塞,直到任务执行结束。因此,只要 future.get() 方法正常返回,也就意味着传入到线程池中的任务已经执行完成了!
5.2.2.3. CountDownLatch
可以引入一个 CountDownLatch 计数器,它可以通过初始化指定一个计数器进行倒计时,其中有两个方法分别是 await() 阻塞线程,以及 countDown() 进行倒计时,一旦倒计时归零,所以被阻塞在 await() 方法的线程都会被释放
基于这样的原理,我们可以定义一个 CountDownLatch 对象并且计数器为 1,接着在线程池代码块后面调用 await() 方法阻塞主线程,然后,当传入到线程池中的任务执行完成后,调用 countDown() 方法表示任务执行结束。最后,计数器归零 0,唤醒阻塞在 await() 方法的线程。

5.3. 自定义线程池参数设置
5.3.1. 降低系统资源消耗
例如 CPU 使用率、操作系统资源消耗、上下文切换开销
设置一个比较大的队列容量和一个比较小的线程池容量

5.4. 异步化
5.4.1. 本地调用异步化


5.4.2. 远程调用异步化

6. 参考与感谢
6.1. 尚硅谷周阳
https://www.bilibili.com/video/BV18b411M7xz?t=644.5&p=49
[[jvm juc.xmind]]
6.2. 美团技术
https://tech.meituan.com/2020/04/02/java-pooling-pratice-in-meituan.html
 微信
微信 支付宝
支付宝