
并发编程专题-基础-10、内存屏障
其实从头看到尾就会发现,一个技术点的出现往往是为了填补另一个的坑。
为了解决处理器与主内存之间的速度鸿沟,引入了高速缓存,却又导致了缓存一致性问题
为了解决缓存一致性问题,引入了如MESI等技术,又导致了处理器等待问题
为了解决处理器等待问题,引入了写缓冲和无效化队列,又导致了重排序和可见性问题
为了解决重排序和可见性问题,引入了内存屏障
1. 屏障分类
为何而来?为了解决计算机的乱序问题而来。那为什么要有乱序,为了性能,ok。那有什么乱序需要用屏障来避免?并发基础-11、乱序问题
1.1. 编译器屏障(优化屏障)
Optimization barrier,解决编译器优化乱序问题。
编译器编译源代码时,会将源代码进行优化,将源代码的指令进行重排序,以适合于CPU的并行执行。然而,内核同步必须避免指令重新排序,优化屏障(Optimization barrier)是避免编译器的重排序优化操作,保证编译程序时在优化屏障之前的指令不会在优化屏障之后执行。
Linux用宏barrier实现优化屏障,gcc编译器的优化屏障宏定义列出如下(在include/linux/compiler-gcc.h中):
#define barrier() __asm__ __volatile__("": : :"memory")
上述定义中,“__asm__”表示插入了汇编语言程序,“__volatile__”表示阻止编译器对该值进行优化,确保变量使用了用户定义的精确地址,而不是装有同一信息的一些别名。“memory”表示指令修改了内存单元。
1.2. 内存屏障(机器屏障)
Memory barrier,解决CPU的指令执行乱序和内存写入乱序问题。
https://www.jianshu.com/p/06717ac8312c
- **smp_mb(StoreLoad)**:
smp_mb 包含的语义有些“重”,既包含了 Store Buffer 的 flush(首先会使得 CPU 在后续变量变更写入之前,把 Store Buffer 的变更写入 flush 到缓存;CPU 要么就等待 flush 完成后写入,要么就把后续的写入变更放到 Store Buffer 中,直到 Store Buffer 数据顺序刷到缓存。),又包含了 Invalidate Queue 的等待环节,但现实场景下,我们可能只需要与其中一个数据结构打交道即可。于是,CPU 的设计者把 smp_mb 屏障进一步拆分,一分为二, smp_rmb 称之为读内存屏障,smp_wmb 称之为写内存屏障。他们分别的语义也相应做了简化:
mfence指令实现了Full Barrier,相当于StoreLoad Barriers。
- **smp_wmb(StoreStore)**:执行后需等待 Store Buffer 中的写入变更 flush 完全到缓存后,后续的写操作才能继续执行,保证执行前后的写操作对其他 CPU 而言是顺序执行的;
- **smp_rmb(LoadLoad)**:执行后需等待 Invalidate Queue 完全应用到缓存后,后续的读操作才能继续执行,保证执行前后的读操作对其他 CPU 而言是顺序执行的;
1.2.1. mb()与mfence
- **在x86 UP体系架构中**,smp_mb、smp_rmb、smp_wmb被翻译成barrier:
1 | |
__volatile告诉编译器此条语句不进行任何优化,””: : :”memory” 内存单元已被修改、需要重新读入。
- **在x86 SMP体系架构中**,smp_mb、smp_rmb、smp_wmb如下定义:
1 | |
362
364行针对x86的32位CPU,366368行针对x86的64位CPU。在x86的64位CPU中,mb()宏实际为:
1 | |
- 在x86的32位CPU中,mb()宏实际为:
1 | |
1.3. JVM屏障
JVM 按前后分别有读、写两种操作以全排列方式一共提供了四种 Barrier,名称就是左右两边操作的名字拼接。比如 LoadLoad Barrier 就是放在两次 Load 操作中间的 Barrier,LoadStore 就是放在 Load 和 Store 中间的 Barrier。Barrier 类型及其含义如下:
LoadLoad,操作序列 Load1, LoadLoad, Load2,用于保证访问 Load2 的读取操作一定不能重排到 Load1 之前。类似于前面说的Read Barrier,需要先处理 Invalidate Queue 后再读 Load2;StoreStore,操作序列 Store1, StoreStore, Store2,用于保证 Store1 及其之后写出的数据一定先于 Store2 写出,即别的 CPU 一定先看到 Store1 的数据,再看到 Store2 的数据。可能会有一次 Store Buffer 的刷写,也可能通过所有写操作都放入 Store Buffer 排序来保证;LoadStore,操作序列 Load1, LoadStore, Store2,用于保证 Store2 及其之后写出的数据被其它 CPU 看到之前,Load1 读取的数据一定先读入缓存。甚至可能 Store2 的操作依赖于 Load1 的当前值。这个 Barrier 的使用场景可能和上一节讲的 Cache 架构模型很难对应,毕竟那是一个极简结构,并且只是一种具体的 Cache 架构,而 JVM 的 Barrier 要足够抽象去应付各种不同的 Cache 架构。如果跳出上一节的 Cache 架构来说,我理解用到这个 Barrier 的场景可能是说某种 CPU 在写 Store2 的时候,认为刷写 Store2 到内存,将其它 CPU 上 Store2 所在 Cache Line 设置为无效的速度要快于从内存读取 Load1,所以做了这种重排。StoreLoad,操作序列 Store1, StoreLoad, Load2,用于保证 Store1 写出的数据被其它 CPU 看到后才能读取 Load2 的数据到缓存。如果 Store1 和 Load2 操作的是同一个地址,StoreLoad Barrier 需要保证 Load2 不能读 Store Buffer 内的数据,得是从内存上拉取到的某个别的 CPU 修改过的值。StoreLoad一般会认为是最重的 Barrier 也是能实现其它所有 Barrier 功能的 Barrier。
对上面四种 Barrier 解释最好的是来自这里:jdk/MemoryBarriers.java at 6bab0f539fba8fb441697846347597b4a0ade428 · openjdk/jdk · GitHub
| 屏障类型 | 指令示例 | 说明 |
|---|---|---|
| LoadLoad Barriers | Load1;LoadLoad;Load2 | 该屏障确保Load1数据的装载先于Load2及其后所有装载指令的的操作 |
| StoreStore Barriers | Store1;StoreStore;Store2 | 该屏障确保Store1立刻刷新数据到内存(使其对其他处理器可见)的操作先于Store2及其后所有存储指令的操作 |
| LoadStore Barriers | Load1;LoadStore;Store2 | 确保Load1的数据装载先于Store2及其后所有的存储指令刷新数据到内存的操作 |
| StoreLoad Barriers | Store1;StoreLoad;Load2 | 该屏障确保Store1立刻刷新数据到内存的操作先于Load2及其后所有装载装载指令的操作。它会使该屏障之前的所有内存访问指令(存储指令和访问指令)完成之后,才执行该屏障之后的内存访问指令 |
StoreLoad 为什么能实现其它 Barrier 的功能?
这个也是从前一个问题结果能看出来的。StoreLoad 因为对读写操作均有要求,所以它能实现其它 Barrier 的功能。其它 Barrier 都是只对读写之中的一个方面有要求。
不过这四个 Barrier 只是 Java 为了跨平台而设计出来的,实际上根据 CPU 的不同,对应 CPU 平台上的 JVM 可能可以优化掉一些 Barrier。比如很多 CPU 在读写同一个变量的时候能保证它连续操作的顺序性,那就不用加 Barrier 了。比如 Load x; Load x.field 读 x 再读 x 下面某个 field,如果访问同一个内存 CPU 能保证顺序性,两次读取之间的 Barrier 就不再需要了,根据字节码编译得到的汇编指令中,本来应该插入 Barrier 的地方会被替换为 nop,即空操作。在 x86 上,实际只有 StoreLoad 这一个 Barrier 是有效的,x86 上没有 Invalidate Queue,每次 Store 数据又都会去 Store Buffer 排队,所以 StoreStore, LoadLoad 都不需要。x86 又能保证 Store 操作都会走 Store Buffer 异步刷写,Store 不会被重排到 Load 之前,LoadStore 也是不需要的。只剩下一个 StoreLoad Barrier 在 x86 平台的 JVM 上被使用。
来自这里:jdk/assembler_x86.hpp at 9a69bb807beb6693c68a7b11bee435c0bab7ceac · openjdk/jdk · GitHub 看到 x86 下使用的是 lock 来实现 StoreLoad,并且只处理了 StoreLoad。
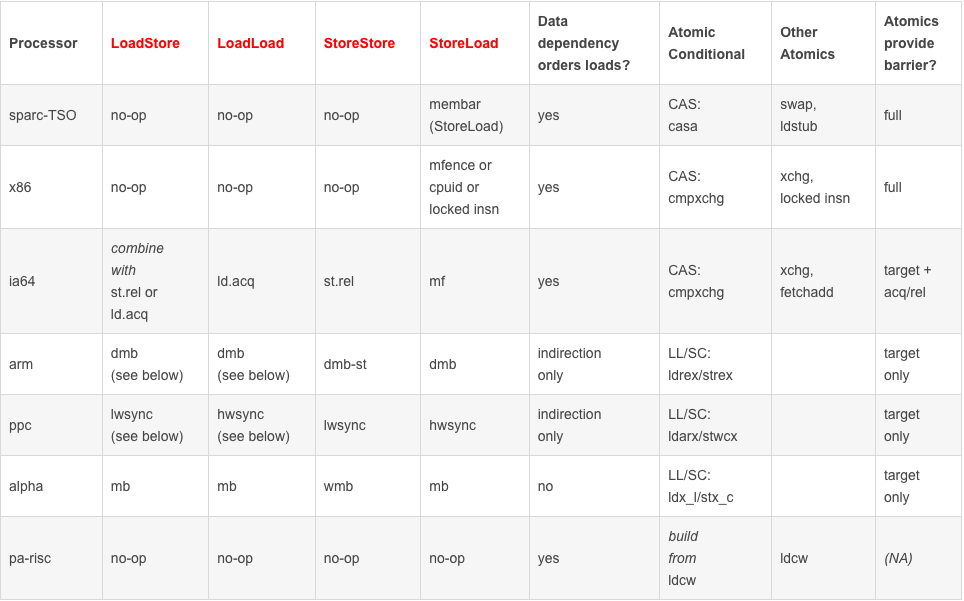
对于x86架构的cpu来说,在单核上来看,其保证了Sequential consistency,因此对于开发者,我们可以完全不用担心单核上的乱序优化会给我们的程序带来正确性问题。在多核上来看,其保证了x86-tso模型,使用mfence就可以将store buffer中的数据,写入到cache中。而且,由于x86架构下,store buffer是FIFO的和不存在invalid queue,mfence能够保证多核间的数据可见性,以及顺序性。
对于arm和power架构的cpu来说,编程就变得危险多了。除了存在数据依赖,控制依赖以及地址依赖等的前后指令不能被乱序之外,其余指令间都有可能存在乱序。而且,它们的store buffer并不是FIFO的,而且还可能存在invalid queue,这些也同样让并发编程变得困难重重。因此需要引入不同类型的barrier来完成不同的需求。
根据上面表格我们可以看到 x86 平台下,只有 StoreLoad 才有具体的指令对应,而其他三个屏障均是 no-op (空操作)。
关于 StoreLoad 又有三个具体的指令对应,分别是 mfence、cpuid、以及 locked insn,他们都能很好地实现 StoreLoad 的屏障效果。但毕竟不可能同时用三种指令,这里可能意思是,三种均能达到效果,具体实现交由 JVM 设计者决断。
我们随便写一段代码,查看下JVM采用的是哪一种命令(需要下载 hsdis-amd64.dylib 然后移动到 jre lib 目录)
1 | |
1 | |
可以看到这里的 StoreLoad 用到的具体指令是lock
1 | |
lock用于在多处理器中执行指令时对共享内存的独占使用。它的副作用是能够将当前处理器对应缓存的内容刷新到内存,并使其他处理器对应的缓存失效。另外还提供了有序的指令无法越过这个内存屏障的作用。
简单来说,这句指令的作用就是保证了可见性以及内存屏障。
- 执行 a 的写操作后执行到 StoreLoad 内存屏障;
- 发出 Lock 指令,锁总线 或 a 的缓存行,那么其他 CPU 不能对已上锁的缓存行有任何操作;
- 让其他 CPU 持有的 a 的缓存行失效;
- 将 a 的变更写回主内存,保证全局可见;
上面执行完后,该 CPU 方可执行后续操作。
JVM 是如何分别插入上面四种内存屏障到指令序列之中的呢?这里的设计相当巧妙。
对于 volatile 读 or monitor enter
1 | |
对于 volatile 写 or monitor exit
1 | |
1.3.1. 其他分类
1、按照可见性划分,也就是解决并发问题的可见性:
加载屏障(Load Barrier):相当于上面的LoadStoreBarrier,也对应JMM 8种基本操作中的load(载入)
存储屏障(Store Barrier):相当于上面的StoreLoadBarrier,也对应JMM 8种基本操作中的Store(存储)
2、按照有序性划分,也就是解决了并发问题中的有序性:
获取屏障(Acquire Barrier):相当于上面的LoadLoadBarrier和LoadStoreBarrier组合
释放屏障(Release Barrier):相当于LoadStoreBarrier和StoreStoreBarrier组合
https://blog.csdn.net/it_lihongmin/article/details/109169260
1.3.2. StoreLoad 最重
所谓的重实际就是跟内存交互次数,交互越多延迟越大,也就是越重。StoreStore, LoadLoad 两个都不提了,因为它俩要么只限制读,要么只限制写,也即只有一次内存交互。只有 LoadStore 和 StoreLoad 看上去有可能对读写都有限制。但 LoadStore 里实际限制的更多的是读,即 Load 数据进来,它并不对最后的 Store 存出去数据的可见性有要求,只是说 Store 不能重排到 Load 之前。而反观 StoreLoad,它是说不能让 Load 重排到 Store 之前,这么一来得要求在 Load 操作前刷写 Store Buffer 到内存。不去刷 Store Buffer 的话,就可能导致先执行了读取操作,之后再刷 Store Buffer 导致写操作实际被重排到了读之后。而数据一旦刷写出去,别的 CPU 就能看到,看到之后可能就会修改,下一步 Load 操作的内存导致 Load 操作的内存所在 Cache Line 无效。如果允许 Load 操作从一个可能被 Invalidate 的 Cache Line 里读数据,则表示 Load 从实际意义上来说被重排到了 Store 之前,因为这个数据可能是 Store 前就在 Cache 中的,相当于读操作提前了。为了避免这种事发生,Store 完成后一定要去处理 Invalidate Queue,去判断自己 Load 操作的内存所在 Cache Line 是否被设置为无效。这么一来为了满足 StoreLoad 的要求,一方面要刷 Store Buffer,一方面要处理 Invalidate Queue,则最差情况下会有两次内存操作,读写分别一次,所以它最重。
2. 内存模型
Acquire与Release语义
对于Acquire来说,保证Acquire后的读写操作不会发生在Acquire动作之前
对于Release来说,保证Release前的读写操作不会发生在Release动作之后
Acquire & Release 语义保证内存操作仅在acquire和release屏障之间发生
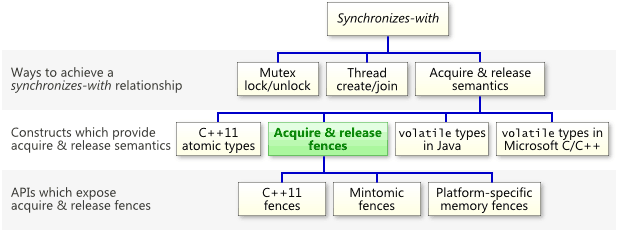
X86-64中Load读操作本身满足Acquire语义,Store写操作本身也是满足Release语义。但Store-Load操作间等于没有保护,因此仍需要靠mfence或lock等指令才可以满足到Synchronizes-with规则。

3. LOCK指令
- 锁总线,其它CPU对内存的读写请求都会被阻塞,直到锁释放,因为锁总线的开销比较大,后来的处理器都采用锁缓存替代锁总线,在无法使用缓存锁的时候会降级使用总线锁
- lock期间的写操作会回写已修改的数据到主内存,同时通过缓存一致性协议让其它CPU相关缓存行失效
x86 体系下的 LOCK 信号(在汇编里给指令加上 LOCK 前缀),通过锁定总线,禁止其他 CPU 对内存的操作来保证原子性。但这样的锁粒度太粗,其他无关的内存操作也会被阻塞,大幅降低系统性能,而随着核数逐渐增加该问题会愈发显著 —— 要知道现在连家用 CPU 都有16核了。
因此 Intel 在 Pentium 486 开始引入了用于保证缓存一致性的 MESI 协议,通过锁定对应的 cache line,使得其他 core 无法修改指定内存,从而实现了原子操作(缓存锁)
总线锁、缓存锁可以保证原子性,缓存一致性协议可以保证可见性,
3.1. 总线锁
总线索就是使用处理器提供的一个LOCK#信号,当一个处理器在总线上输出此信号,其他处理器的请求将被阻塞,那么该处理器就可以独占共享锁。
在多 cpu 下,当其中一个处理器要对共享内存进行操作的时候,在总线上发出一个 LOCK# 信号,这个信号使得其他处理器无法通过总线来访问到共享内存中的数据,总线锁定把 CPU 和内存之间的通信锁住了,这使得锁定期间,其他处理器不能操作其他内存地址的数据,总线锁定的开销比较大,这种机制显然是不合适的。
1 | |
3.2. 缓存锁
由于,我们只需要保证对某个内存地址的操作是原子的即可,但是总线锁把CPU和内存之间的通信锁住了,这使得在锁定期间,其他处理器也不能操作其他内存地址的数据,所以总线锁的开销比较大。目前,处理器在某些场合下使用缓存锁来代替总线索进行优化。
缓存锁就是指内存区域如果被缓存在处理器的缓存行中,并且在LOCK#操作期间,那么当它执行操作回写到内存时,处理器不在总线上声言LOCK#信号,而是修改内部的内存地址,并允许它的缓存一致性机制来保证操作的原子性,因为缓存一致性机制会阻止同时修改由两个以上处理器缓存的内存区域数据,其他处理器回写已被锁定的缓存行的数据时,就会使缓存无效
相比总线锁,缓存锁即降低了锁的力度。核心机制是基于缓存一致性协议来实现的。
3.3. 使用场景
如上面所说,在多数情况下,处理器还是使用缓存锁来代替总线锁,但是在下面两种情况下,我们还是使用总线锁来完成相应保证一致性。
- 情况1:当操作的数据不能被缓存在处理器内部,或者操作的数据跨多个缓存行时,则处理器会字调用总线锁锁定。
- 情况2:有些处理器不支持缓存行锁定。
3.4. lock的实现
1 | |
[[../../../../cubox/006-ChromeCapture/内存屏障 – Part 1 - innohub]]
[[../../../../cubox/006-ChromeCapture/内核同步机制-优化屏障和内存屏障-阿里云开发者社区]]
4. 实战经验
5. 参考与感谢
 微信
微信 支付宝
支付宝
