
并发编程专题-基础-3、对象内存
1. OOP-Klass 模型
这里的 Oop 并非是 Object-oriented programming,而是 Ordinary object pointer(普通对象指针),是 HotSpot 用来表示 Java 对象的实例信息的一个体系。其中 oop 是 Oop 体系中的最高父类,整个继承体系如下所示:
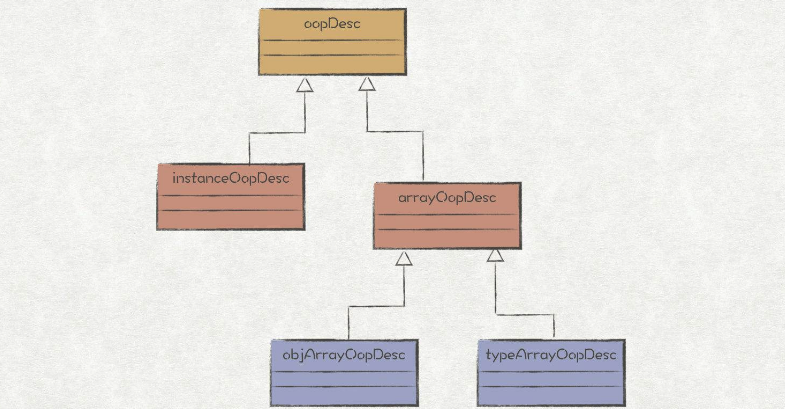
https://juejin.cn/post/6844904054561193992
1.1. JVM 实现⭐️🔴
^phycx3
- JVM 在加载 class 时,通过类的全限定名获取存储该类的 class 文件,创建
instanceKlass,表示其元数据,存放在方法区;并在堆区生成该类的 Class 对象,即instanceMirrorKlass对象。 - 在 new 一个对象时,JVM 创建
instanceOopDesc,来表示这个对象,存放在堆区;它用来表示对象的实例信息,看起来像个指针实际上是藏在指针里的对象;instanceOopDesc 对应 java 中的对象实例 - HotSpot 并不把 instanceKlass 暴露给 Java,而会另外创建对应的 java.lang.Class 对象(对应
InstanceMirrorKlass),并将 Class 对象称为前者的 “Java 镜像 “ - klass 持有指向 class 对象引用 (java_mirror 便是该 instanceKlass 对 Class 对象的引用),镜像机制被认为是良好的面向对象的反射与元编程设计的重要机制
- HotSopt JVM 的设计者不想让每个对象中都含有一个 vtable(虚函数表),所以就把对象模型拆成 klass 和 oop,其中 oop 中不含有任何虚函数,而 Klass 就含有虚函数表,可以进行 method dispatch。❕
[[深入理解JVM(九)一一 对象实例化和内存布局 - 掘金]]
HotSpot 采用 Oop-Klass 模型来表示 Java 对象,其中 Klass 对应着 Java 对象的类型(Class),而 Oop 则对应着 Java 对象的实例(Instance)。Oop 是一个继承体系,其中 oop 是体系中的最高父类,它的存储结构可以分成对象头和对象体。对象头存储的是对象的一些元数据,对象体存储的是具体的成员属性。值得注意的是,如果成员属性属于普通对象类型,则 oop 只存储它的地址。
我们都知道 Java 中的普通方法(没有 static 和 final 修饰)是动态绑定的,在 C++ 中,动态绑定通过 虚函数 来实现,代价是每个 C++ 对象都必须维护一张 虚函数表。
Java 的特点就是一切皆是对象,如果每个对象都维护一张虚函数表,内存开销将会非常大。JVM 对此做了优化,虚函数表不再由每个对象维护,改成由 Class 类型维护,所有属于该类型的对象共用一张虚函数表。因此我们并没有在 oop 上找到方法调用的相关逻辑,这部分的代码被放在了 klass 里面。
[[Java的对象模型——Oop-Klass模型(一) - 掘金]]
1.2. 结构关系
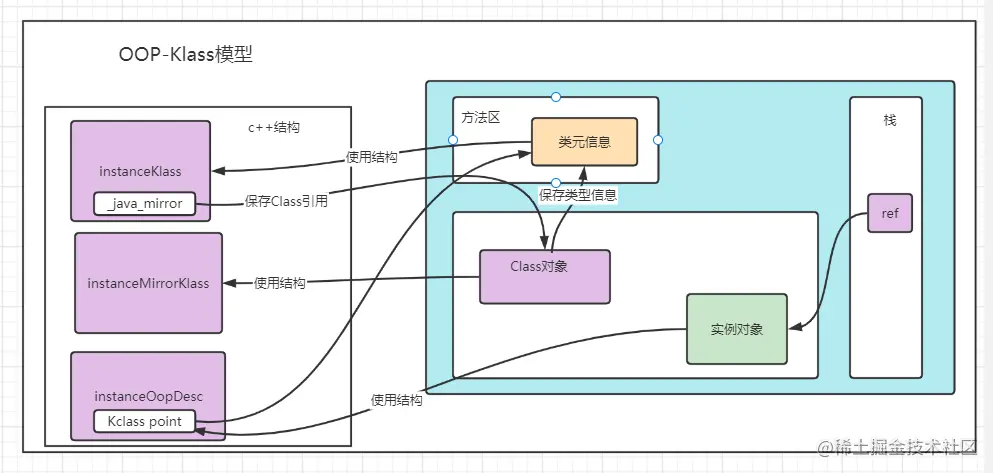
oop→instanceOop 对应类实例对象,klass→instanceKlass 对应 java 类 Class
2. 创建对象逻辑
在加载处理完 ClassX 类的一系列逻辑之后,Hotspot 会在堆中为其实例对象 x 开辟一块内存空间存放实例数据,即 JVM 在实例化 ClassX 时,会创建一个 instanceOop,这个 instanceOop 就是 ClassX 对象实例 x 在内存中的对等体,用来存储实例对象的成员变量。让我们来看下 instanceOop.hpp(位于 OpenJDKhotspotsrcsharevmoops 目录下),发现 instanceOop 是继承自 oopDesc 的(class instanceOopDesc : public oopDesc),继续看下 Oop 的结构就会发现:
1 | |
_mark 和 _metadata 加起来就是我们传说中的对象头了,其中 markOop 的变量 _mark 用来标识 GC 分代信息、线程状态、并发锁等信息。而 _metadata 的联合结构体则用来标识元数据(指向 instanceKlass 元数据的指针),就是这个类包含的父类、方法、变量、接口等各种信息。
3. 对象内存布局
Hotspot 虚拟机中,对象在内存中存储的布局可以分为三块区域:对象头(Header)、实例数据(Instance Data)和对齐填充(Padding)。
- 对象头:比如 hash 码,对象所属的年代,对象锁,锁状态标志,偏向锁(线程)ID,偏向时间,数组长度(数组对象才有)等。
- 实例数据:存放类的属性数据信息,包括父类的属性信息;
- 对齐填充:由于虚拟机要求 对象起始地址必须是 8 字节的整数倍。填充数据不是必须存在的,仅仅是为了字节对齐。
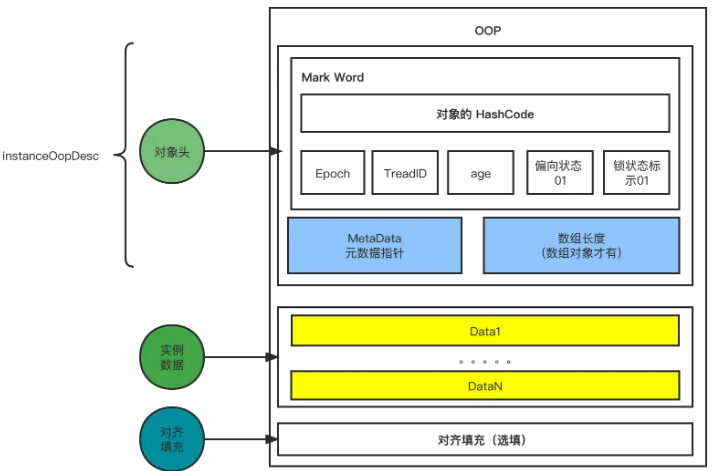
❕
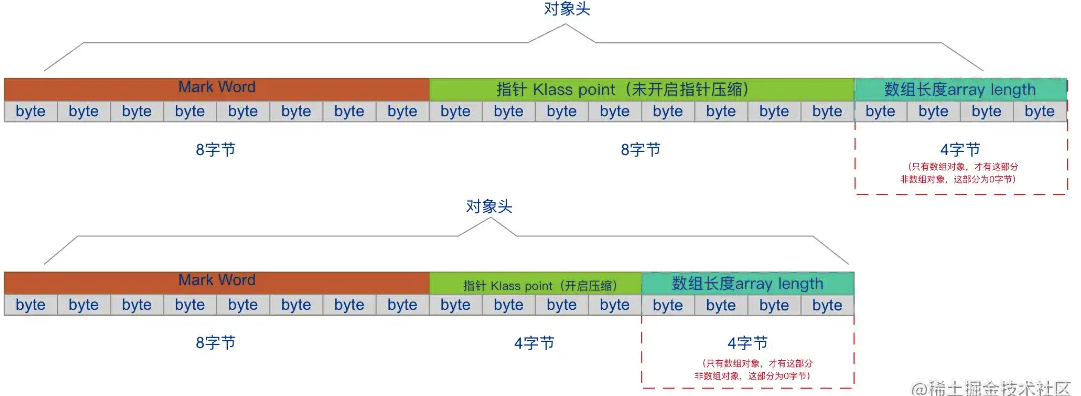
3.1. 对象头
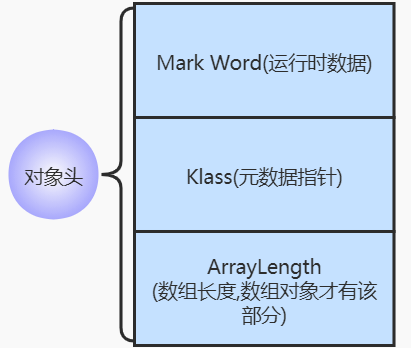
- Mark Word(核心) : 记录了这个对象当前锁机制的记录信息
- Klass : klass pointer 指向元数据区中 (JDK1.8) 该对象所代表的类的描述元数据对象 InstanceKlass
- ArrayLength : 这个部分是基于数组对象,而对于普通对象,该部分的是没有占位的
- Mark Word 里默认存储锁状态信息是无锁状态的,即存储的是 HashCode、分代年龄、是否偏向锁、锁标志位等信息,64bit 默认存储结构如下图 :
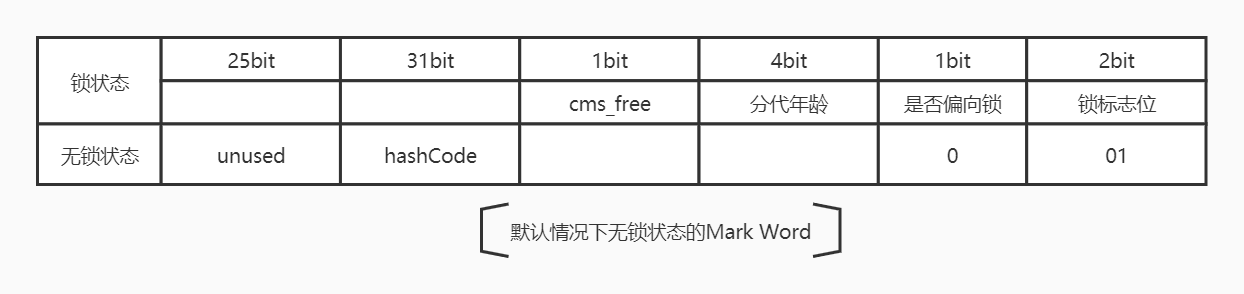
- 在运行期间,Mark Word 里存储的数据会随着是否偏向锁、锁标志位的变化而变化,如下图五种状态中其中一种,即同一时刻 MarkWord 只能表示其中一种锁状态。
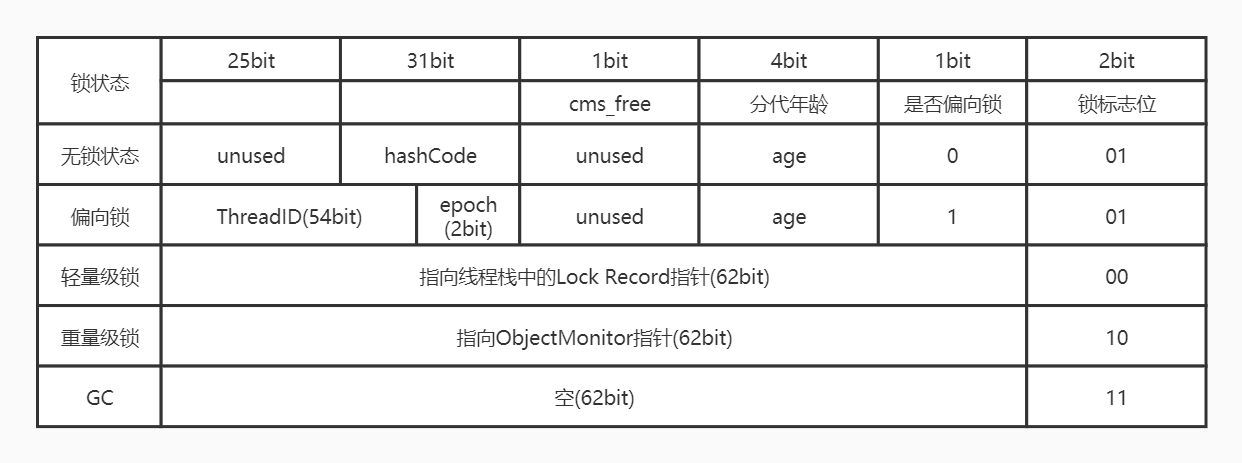
3.1.1. Mark Word⭐️🔴
synchronized 同步锁相关信息保存到锁对象的对象头里面的 Mark Word 中,锁升级功能主要是依赖 Mark Word 中锁标志位和是否偏向锁标志位来实现的。
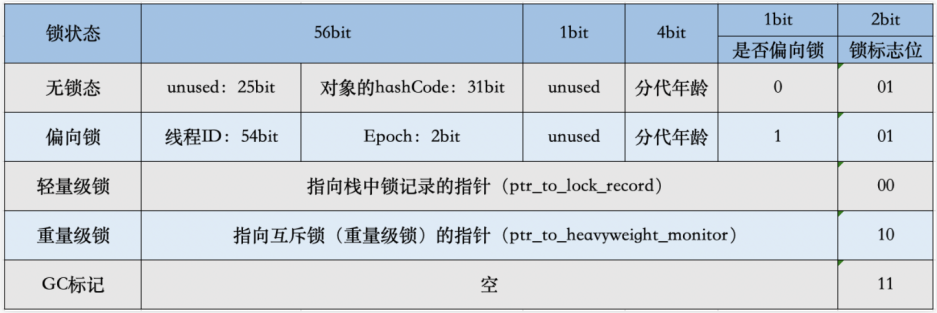
从上图我们可以看到,无锁对应的锁标志位是“01”,是否偏向锁标志是“0”。
1 | |
对象头中 MarkWord 部分总共占 8 个字节,共 64 位,我们按照上图中“1 -> 8”,也就是从后面往前面拼接起来: ❕

3.1.1.1. 分代年龄
记录分代年龄一共 4 bit,所以最大为 2^4 - 1 = 15。所以配置最大分代年龄 -XX:MaxTenuringThreshold=n 这个 n 不能大于 15,当然也不能小于 0.等于 0 的话,就直接入老年代。等于 16 的话,就是从不进入老年代,这样不符合 JVM 规范,所以不能大于 15。默认是 15。
3.2. 32 位 CPU 最大支持 4G 内存⭐️🔴
实际上内存是把 8 个 bit 排成 1 组, 每 1 组成为 1 个单位, 大小是 1byte(字节), cpu 每一次只能访问 1 个 byte, 而不能单独去访问具体的 1 个小格子 (bit). 1 个 byte 字节就是内存的最小的 IO 单位.
既然内存的最小 IO 单位是字节 byte,那么我们其实不需要为每一个格子也就是每一 bit 去分配地址了,而是按照 8 个 bit 为一组,也就是一个字节分配一个地址。
其实计算机操作系统会给内存每 1 个字节分配 1 个内存地址, cpu 只需要知道某个数据类型的地址, 就可以直接去到对应的内存位置去提取数据了。
我们再算一下,其实 32 位表示 232 个地址,而每一个地址是指向的是 8bit 为一组的 byte ,所以要算到寻址的话,就要在乘以 8 ,也就是 235 个 bit,这样再换算为 GB 就是 4GB 了。 ❕
字与字长:计算机基础-1、相关名词
3.3. 压缩指针
这一部分用于存储对象的类型指针,该指针指向它的类元数据 instanceKlass,JVM 通过这个指针确定对象是哪个类的实例。该指针的位长度为 JVM 的一个字大小,即 32 位的 JVM 为 32 位,64 位的 JVM 为 64 位。 如果应用的对象过多,使用 64 位的指针将浪费大量内存。为了节约内存可以使用选项 +UseCompressedOops 开启指针压缩,其中,oop 即 ordinary object pointer 普通对象指针。开启该选项后,下列指针将压缩至 32 位。1.6 中某个版本之后默认开启。
压缩指针包括:每个 Class 的属性指针(即静态变量)、 每个对象的属性指针(即对象变量) 、普通对象数组的每个元素指针
当然,也不是所有的指针都会压缩,一些特殊类型的指针 JVM 不会优化,比如指向 PermGen 的 Class 对象指针 (JDK8 中指向元空间的 Class 对象指针)、本地变量、堆栈元素、入参、返回值和 NULL 指针等。❕
3.4. 为什么压缩⭐️🔴
3.4.1. 原因
64 位 JVM 在支持更大堆的同时,由于对象引用变大却带来了性能问题:
增加了 GC 开销
64 位对象引用需要占用更多的堆空间,留给其他数据的空间将会减少,从而加快了 GC 的发生,更频繁的进行 GC。降低 CPU 缓存命中率
64 位对象引用增大了,CPU 能缓存的 oop 将会更少,从而降低了 CPU 缓存的效率。
3.4.2. 原理
为了能够保持 32 位的性能,oop 必须保留 32 位。那么,如何用 32 位 oop 来引用更大的堆内存呢?答案是压缩指针(CompressedOops)
4 字节,8 位最大表示 4GB 内存。那么 Java 是怎么做到 4 个字节表示 32GB 呢?怎有扩大了 8 倍?这就要使用到之前提到的 Java 的对齐填充机制了。
Java 的 8 字节对齐填充,就像是内存的 8bit 为一组,变为 1byte 一样。
这里的压缩指针,不是真实的操作系统内存地址,而是 Java 进行 8byte 映射之后的地址,即 8 个 byte 为一组作为一个表达单位。因此相同的指针数量下,单位表达能力扩大了 8 倍,就相当于操作系统的指针表达能力有进行的 8 倍的扩容。
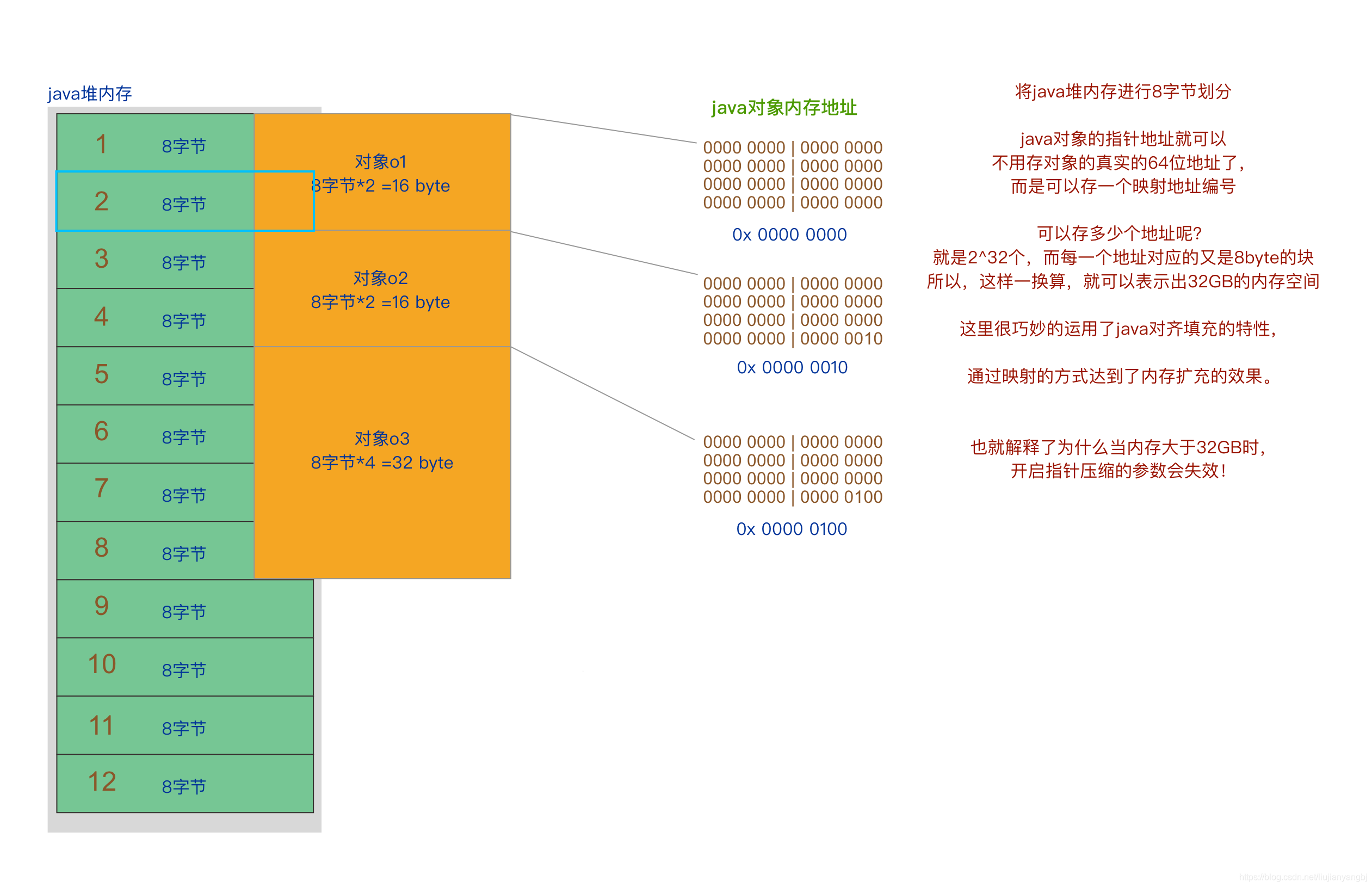
https://blog.csdn.net/liujianyangbj/article/details/108049482
3.4.3. 实现方式
JVM 的实现方式是,不再保存所有引用,而是每隔 8 个字节保存一个引用。例如,原来保存每个引用 0、1、2…,现在只保存 0、8、16…。因此,指针压缩后,并不是所有引用都保存在堆中,而是以 8 个字节为间隔保存引用。
在实现上,堆中的引用其实还是按照 0x0、0x1、0x2…进行存储。只不过当引用被存入 64 位的寄存器时,JVM 将其左移 3 位(相当于末尾添加 3 个 0),例如 0x0、0x1、0x2…分别被转换为 0x0、0x8、0x10。而当从寄存器读出时,JVM 又可以右移 3 位,丢弃末尾的 0。(oop 在堆中是 32 位,在寄存器中是 35 位,2 的 35 次方=32G。也就是说,使用 32 位,来达到 35 位 oop 所能引用的堆内存空间)
https://juejin.cn/post/6844903768077647880
3.5. 哪些指针需要压缩⭐️🔴
首先看下官网 《CompressedOops》 给出的需要被压缩的类型:
Which oops are compressed?
In an ILP32-mode JVM, or if the UseCompressedOops flag is turned off in LP64 mode, all oops are the native machine word size.
If UseCompressedOops is true, the following oops in the heap will be compressed:
- the klass field of every object
- every oop instance field
- every element of an oop array (objArray)
我们可以看出指针压缩只有在 64 位 JVM 下才有效,在 32 位 JVM 或未开启指针压缩的 64 位 JVM 下 oop 大小都是原生的机器字大小。而具体压缩的则是 klass field、oop instance field、以及每个数组中元素的 oop。❕
3.6. 为什么 8 字节对齐
假如我们这里有 3 个对象 A、B、C,他们的大小分别为 8、16、8 字节(为什么假设这几个值,我们先按下不表),并且在内存中连续存储,为更好理解,我们简化为下图:
方案 1,指针用 内存位置 来标记对象在内存中的位置:
A:00000000 00000000 00000000 00000000 (十进制表示:0)
B:00000000 00000000 00000000 00001000 (十进制表示:8)
C:00000000 00000000 00000000 00011000 (十进制表示:24)
从上面可以看出 32 位的指针,满打满算也只能存储 2^32,约 4GB 的内存地址。
如果是 64 位的指针,就能表示 2^64,上面说的可以理解为无限大,甚至感觉还有点浪费。
既然 64 位指针用来存储太浪费了,有什么更好的办法可以在 32 位的限制下表示更多的内存地址吗? 这时,我们发现对象 A、B、C 大小都是 8 字节的整数倍,即 8 是他们对象大小的最大公约数!
我们可以借助索引来标识。 用 8 位内存地址偏移量 代表 1 索引
那么 A 的位置就可以标识为 索引 0,B 为 索引 1,C 为 索引 3。
方案 2,指针用 索引 来标记对象在内存中的位置:
A:00000000 00000000 00000000 00000000 (十进制表示:0)
B:00000000 00000000 00000000 00000001 (十进制表示:1)
C:00000000 00000000 00000000 00000011 (十进制表示:3)
加入索引这一概念是为了方便理解;实际上 JVM 是通过读取时左移 3 位,存储时右移 3 位来完的。
原因 1也就是说原本可表示 4GB 的内存地址,因为 1 索引表示 8 个内存地址偏移量,现在可以表示最高存储 32GB 的内存地址了。
上面的对象 A、B、C 我们假设的大小是 8 字节、16 字节、8 字节;共同点你可能发现了,他们都是 8 字节的倍数,其实 Java 对象的大小就必须是 8 字节的整数倍,如果没有这个条件,上面说的索引说法也不成立。
原因 2
当然除了为了支持上面这些功能外,另外还有的就是因为现在大多数计算机都是高效的 64 位处理器,一次能处理 64 位的指令,即 8 个字节的数据,如果数据的存放地址不做字节对齐,对正常的工作不会产生任何影响,但是性能会降低,CPU 需要多个周期来读取后将数据拼接起来才能读取到数据。HotSpot VM 的自动内存管理系统也就遵循了这个要求,这样子性能更高,处理更快。
4. 多少字节 (对象大小计算)⭐️🔴⭐️🔴
4.1. new Object()
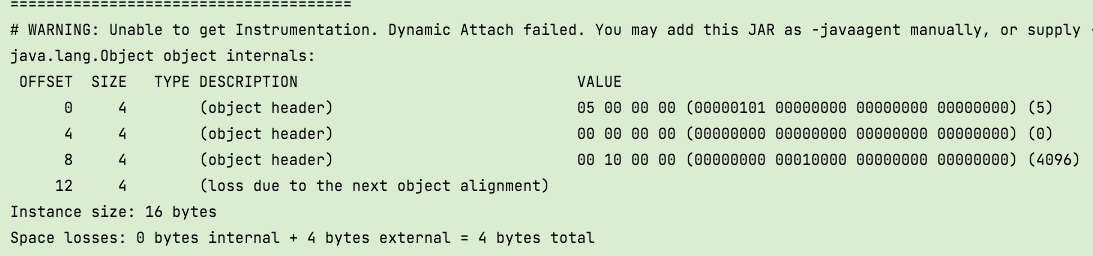
正确答案
在 JDK8 下 64 位操作系统中 new Object() 占多少字节?
答案:16 字节
8 个字节是 MarkWord + 4 个字节是指针(jdk 8 默认开启指针压缩)+ 4 个字节是对齐填充位
4.2. 加其他属性
int 占 4 字节,short 占 2 字节,long 占 8 字节,byte 占 1 字节,float 占 4 字节,double 占 8 字节,char 占 2 字节,boolean 占 1 字节
注意空对象的 4 个填充位可以用占用小于等于 4 的属性来填充,比如 short 类型的话占用 2 个字节,会再额外用 2 个字节补齐 ❕
[[20221110-如何计算一个对象的大小? - 掘金]]
5. 哈希几次
[[20221112-Java GC详解 - 最全面的理解Java对象结构 - 对象指针 OOPs HeapDump性能社区]]
6. 虚函数表
一个 klassVtable 可看成是由多个 vtableEntry 组成的数组,其中每个元素 vtableEntry 里面都包含了一个方法的地址。在进行虚分派时,JVM 会根据方法在 klassVtable 中的索引,找到对应的 vtableEntry,进而得到方法的实际地址,最后根据该地址找到方法的字节码并执行。
vtalbe 结构
[[Java的对象模型——Oop-Klass模型(二) - 掘金]]
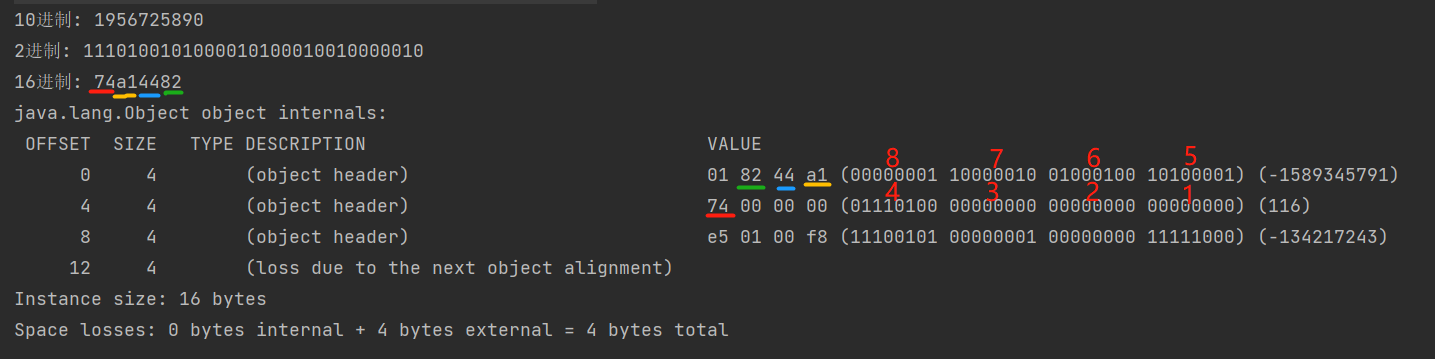
7. 使用 JOL 分析对象布局
1 | |
1 | |
8. 参考与感谢
[[../../../../cubox/006-ChromeCapture/20221110-为什么要字节对齐? - 掘金]]
[[../../../../cubox/006-ChromeCapture/20221110-为什么JVM要用到压缩指针?Java对象要求8字节的整数倍? - 掘金]]
[[../../../../cubox/006-ChromeCapture/20221110-Java 对象头 - 简书]]
 微信
微信 支付宝
支付宝
