
并发编程专题-基础-1、JMM与MESI
1. CPU 架构
1.1. CPU 主要架构
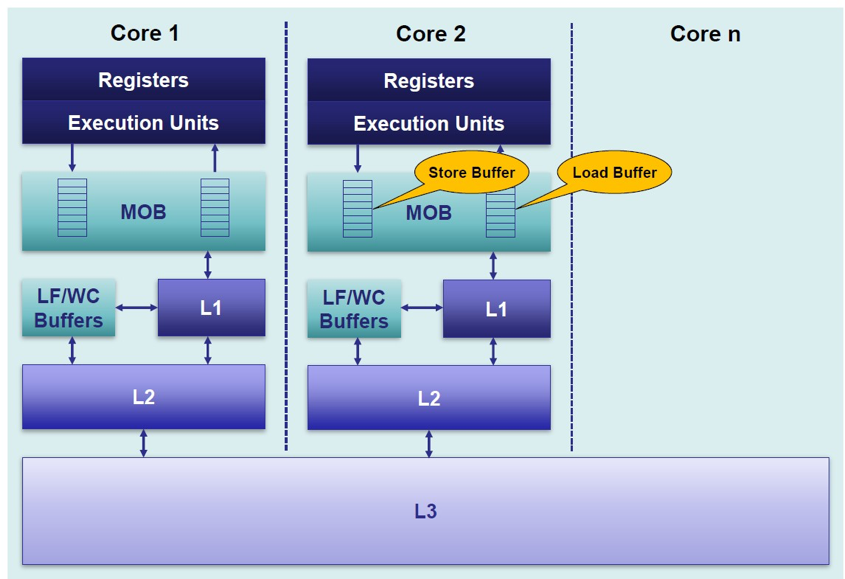

1.1.1. Front End(Core 前端)
首先看 Front-end,Front-end 的主要目的就是从内存里提取各种各样的 X86 指令,然后对指令进行译码,融合优化等操作,把 X86 指令转化为最适合执行单元执行的微指令流传递给执行单元。Front-End 的存在就是为了让执行单元时刻保持繁忙,将 CPU 的性能完全发挥出来。
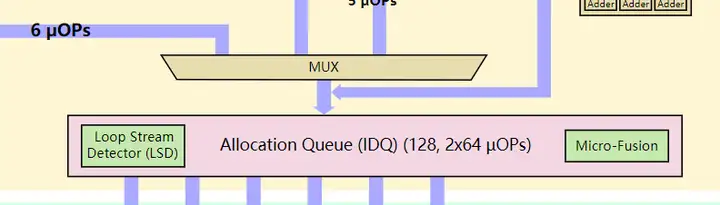
1.1.1.1. 乱序组件
- **Allocation Queue(IDQ): 分配队列,分配队列作为前端与执行单元的接口,是 Core 前端的最后的一个部件。分配队列的目的是将微指令进行重新整合与融合,发给执行单元进行乱序执行。分配队列又包含了 Loop Stream Detector(LSD) 循环流检测器,对循环操作进行优化与 up-Fusion(微指令融合单元)。融合是为了让后续解码单元更有效率并且节省 ROB(re-order buffer)的空间
1.1.2. Execution Engine (执行单元)
Front-End 的存在就是为了让执行单元时刻保持繁忙,那么执行单元的最主要的目的就是执行指令,运算。这也是一个 core 中最根本的单元。
当被 AQ 或者 IDQ(分配单元)优化过后的微指令来到执行单元时,首先最先传输到
1.1.2.1. 重排缓冲区
- **ROB(re-order buffer):重新排序缓冲区。ROB 的存在 ROB 的目的为存储 out-of-order 的处理结果,作为 EU 的入口兼部分出口,它是乱序执行的最基本保证。当指令被传如 ROB 中,微指令流会以顺序执行的方式传入到后面的 RS,在经过 ROB 时,会占用 ROB 的一个位置,这个位置是存储微指令乱序执行处理完成时候的结果,之后经过整合会顺序写回到相应的寄存器。而微指令在经过 ROB 时候会做一些优化。(消除寄存器移动,置零指令与置一指令等)。此外对于超线程中的寄存器别名技术在此经过 RAT(寄存器别名表)进行寄存器重命名。
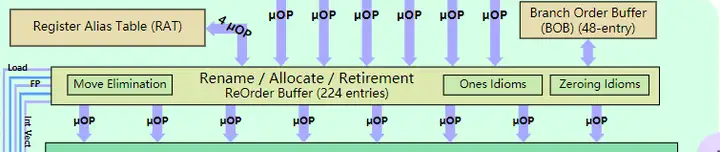
- RS(Scheduler unified reservation station):统一调度保留站。指令经过前面千辛万苦来到这里,此时微指令不在融合在一起,而是被单独的分配给下面各个执行单元,从架构图中可以看到,RS 下面挂载了八个端口,每个端口后面挂载不同的执行模块应对不同的指令需求.
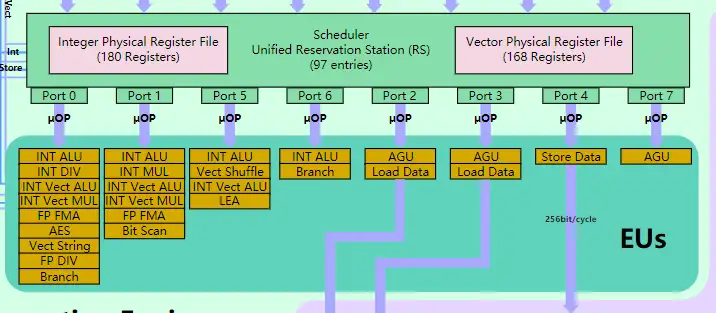
从上图中可以看到,对于 8 个端口,其中 Port0,Port1,Port5,Port6 负责各种常见运算 (整数,浮点,除法,移位,AES 加密,复合整数运算……),而 Port2,Port3 负责从下层的指令缓存提取数据,port4 负责存储数据到 L1 缓存。Port7 挂载地址生成单元(AGU address generation unit).
1.1.3. Memory Subsystem
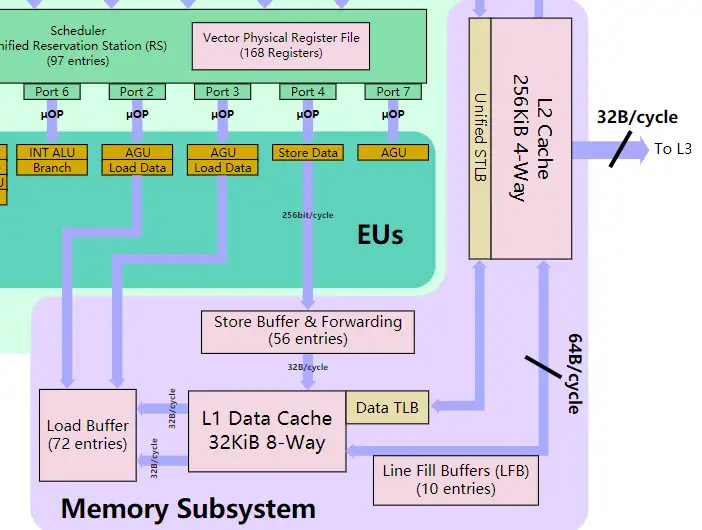
图中紫色的模块,在 EU(执行单元)在执行指令时候,L1 数据 Cache 负责供给执行指令期间所需要的数据。从图中可以看到 L1 数据缓存是 8- 路并行数据缓存,L1 数据缓存可以通过数据页表地址缓存从 L2 提取数据与存储数据。
1.1.3.1. 保存缓冲区
Store Buffer
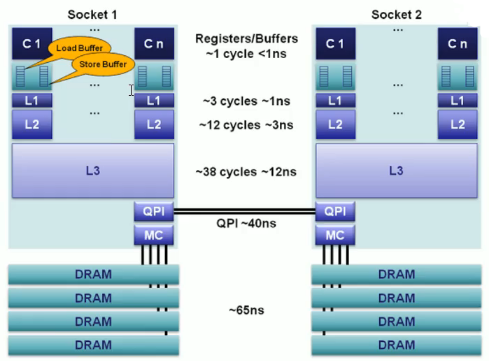
1.2. 高速缓存
1.2.1. 为什么要有
1.2.1.1. 性能适配
CPU 和内存访问性能的差距非常大。如今,一次内存的访问,大约需要 120 个 CPU Cycle。这也意味着,在今天,CPU 和内存的访问速度已经有了 120 倍的差距。
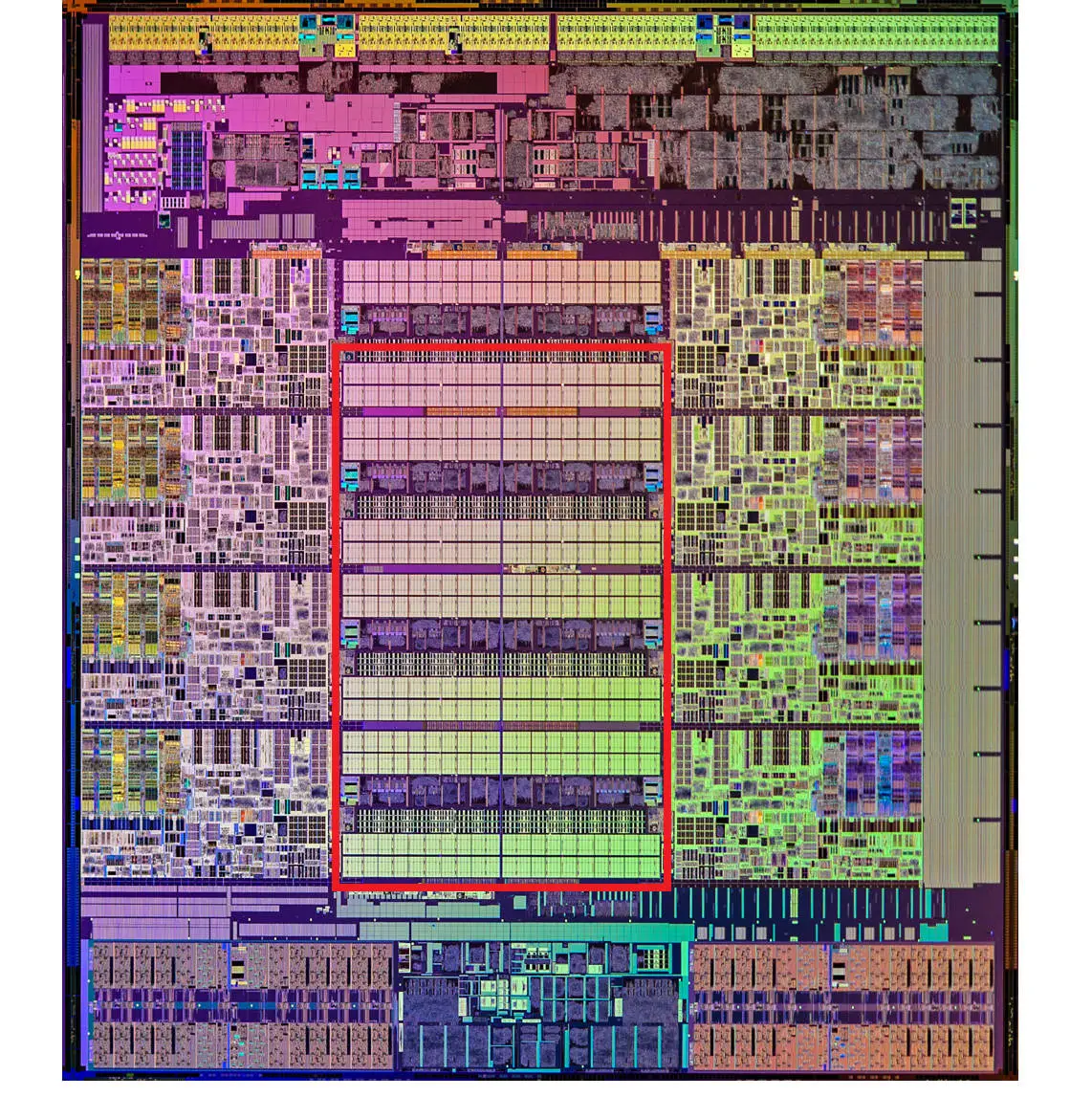
为了弥补两者之间的性能差异,充分利用 CPU,现代 CPU 中引入了 高速缓存 (CPU Cache)。高速缓存分为 L1/L2/L3 Cache,不是一个单纯的、概念上的缓存(比如使用内存作为硬盘的缓存),而是指特定的由 SRAM 组成的物理芯片。下图是一张 Intel CPU 的放大照片。这里面大片的长方形芯片,就是这个 CPU 使用的 20MB 的 L3 Cache,可以看到现代 CPU 中大量的空间已经被 SRAM 占据。
1.2.1.2. 局部性原理
- 时间局部性:某个内存单元在较短时间内很可能被再次访问
- 空间局部性:某个内存单元被访问后相邻的内存单元较短时间内很可能被访问
在各类基准测试 (Benchmark) 和实际应用场景中,CPU Cache 的命中率通常能达到 95% 以上。
1.2.2. 缓存行
1.2.2.1. 是什么
之所以会有 CPU 缓存,时间局部性是其中一个重要的原因。不过,我们到底应该怎么利用处理器的空间局部性呢?比起拷贝一个单独的内存地址到 CPU 缓存里,拷贝一个 缓存行 (Cache Line) 是更好的实现。一个缓存行是一个连续的内存段。
缓存行的大小取决于缓存的级别 (同样的,具体还是取决于处理器模型)。举个例子,这是我的电脑的 L1 缓存行的大小:
1 | |
处理器会拷贝一段连续的 64 字节的内存段到 L1 缓存里,而不是仅仅拷贝一个单独的变量。比如 long 类型变量,1 个占用 8 个字节,那么一个缓存行就可放 8 个 long 类型的变量
现在总结一下,为了平衡 CPU 和内存的性能差异,现在 CPU 引入高速缓存:
- **高速缓存 (CPU Cache)**:用于平衡 CPU 和内存的性能差异,分为 L1/L2/L3 Cache。其中 L1/L2 是 CPU 私有,L3 是所有 CPU 共享。
- **缓存行 (Cache Line)**:高速缓存的最小单元,一次从内存中读取的数据大小。常用的 Intel 服务器 Cache Line 的大小通常是 64 字节。
两种写入策略。
- **写直达 (Write-Through)**:每一次数据都要写入到主内存里面。
- **写回 (Write-Back)**:数据写到 CPU Cache 就结束。只有当 CPU Cache 是脏数据时,才把数据写入主内存。
写回这个策略里,如果我们大量的操作,都能够命中缓存。那么大部分时间里,我们都不需要读写主内存,自然性能会比写直达的效果好很多。
1.2.2.2. 伪共享
[[【译】CPU 高速缓存原理和应用 - Strike Freedom]]
1.3. 乱序执行技术
乱序执行(Out-of-order Execution)是以乱序方式执行指令,即 CPU 允许将多条指令不按程序规定的顺序而分开发送给各相应电路单元进行处理。这样,根据各个电路单元的状态和各指令能否提前执行的具体情况分析,将能够提前执行的指令立即发送给相应电路单元予以执行,在这期间不按规定顺序执行指令;然后由 重新排列单元将各执行单元的结果按指令顺序重新排列。乱序执行的目的,就是为了 使 CPU 内部电路满负荷运转,并相应提高 CPU 运行程序的速度。
实现乱序执行的关键在于 取消传统的“取指”和“执行”两个阶段之间指令需要线性排列的限制,而使用一个 指令缓冲池(即重排缓冲区 ROB) 来开辟一个较长的指令窗口,允许执行单元在一个较大的范围内调遣和执行已译码的程序指令流。
1.4. CPU 乱序来源
1.4.1. 指令执行乱序
因为 MESI 规范要求变量值写入缓存行的前提条件是变量必须在缓存行中,这就要求有一个中间的 StoreBuffer 作为缓冲 (其实这是 StoreBuffer 需要存在的一个原因,主要原因还是为了避免 CPU 写入缓存行时等待其他 CPU 的 ack 消息而导致的性能下降),否则会导致 CPU 效率下降。那么
ROB 写入到 StoreBuffer 有 2 种方式:
- ROB 中的变量,在 StoreBuffer 中谁先有谁先写
- 严格的 FIFO 方式
从 x86-TSO 模型的物理构件角度解释就是,写操作会按照 FIFO 的规则 进入 StoreBuffer,并且按照 FIFO 的顺序刷入共享存储
so,x86 是可以保证不会出现 CPU 的指令执行乱序的
1.4.2. 内存写入乱序
然鹅,从 StoreBuffer 到 共享缓存这一步,是异步的,就需要 CPU 指令来保证了,比如 volatile 的 fence 方法中的 lock 指令,值得注意的是 lock 这个 CPU 指令也具有禁止编译优化的作用。
1.4.2.1. 问题根源
[[后端 - MESI 缓存一致性协议引发的一些思考_个人文章 - SegmentFault 思否]]
2. Java Memory Model
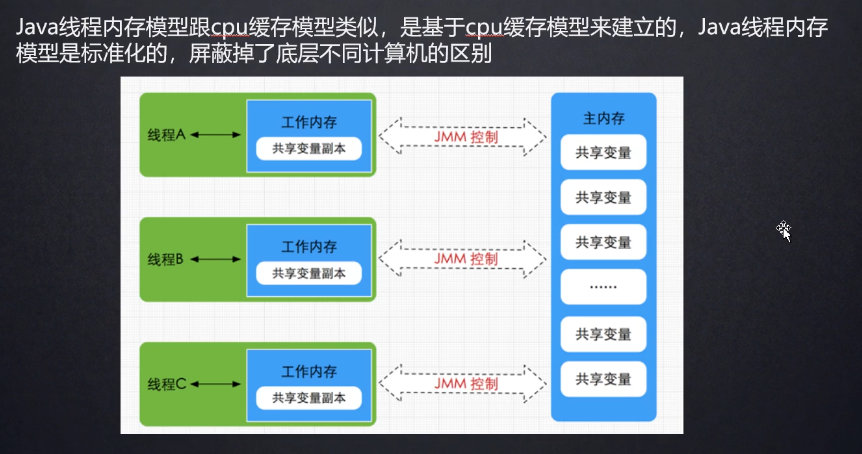
工作内存就是每个线程独享的线程栈
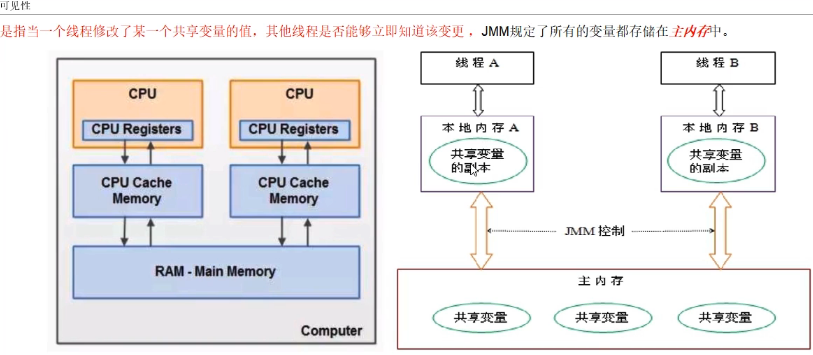
2.1. 并发编程的 3 大特性

2.2. JMM8 大原子操作
- read(读取):作用于主内存变量,把一个变量值从主内存传输到线程的工作内存中,以便随后的 load 动作使用;
- load(载入):作用于工作内存的变量,它把 read 操作从主内存中得到的变量值放入工作内存的变量副本中;
- use(使用):作用于工作内存的变量,把工作内存中的一个变量值传递给执行引擎,每当虚拟机遇到一个需要使用变量的值的字节码指令时将会执行这个操作;
- assign(赋值):作用于工作内存的变量,它把一个从执行引擎接收到的值赋值给工作内存的变量,每当虚拟机遇到一个给变量赋值的字节码指令时执行这个操作;
- store(存储):作用于工作内存的变量,把工作内存中的一个变量的值传送到主内存中,以便随后的 write 的操作;
- write(写入):作用于主内存的变量,它把 store 操作从工作内存中一个变量的值传送到主内存的变量中;
2.3. JMM 缓存不一致问题

2.3.1. 工作原理
2.3.1.1. 总线加锁
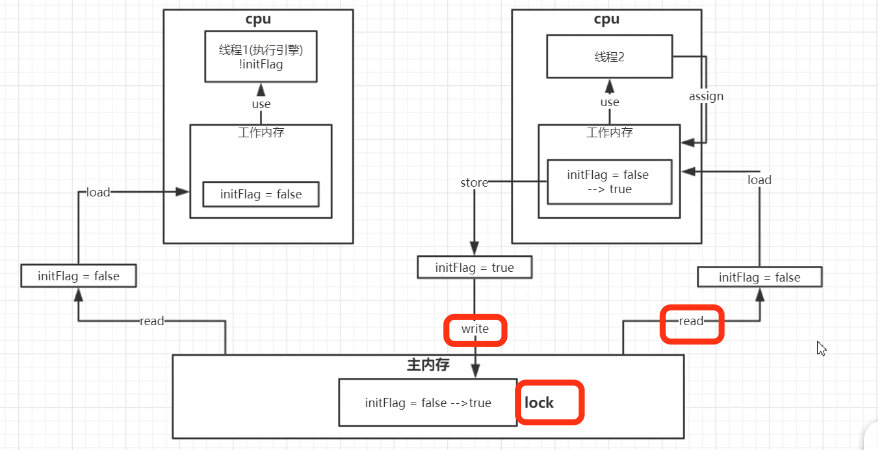
- 先到先得,一个线程 read 主内存数据时,用 lock 命令给总线加锁,此时 CPU 跟主内存的通信被锁定,其他 CPU 的线程都无法操作主内存,直到将运算结果 write 回主内存后再用 unlock 命令将锁释放,之后其他线程才能操作主内存中的这个资源。
- 从主内存中,读取锁的最小单位是缓存行,加入一个数据的长度大于一个缓存行,这时候就会出现缓存行失效问题,当缓存行失效,就会走总线加锁。
2.3.1.2. MESI
3. MESI
https://www.cnblogs.com/jackeason/p/11336317.html
MESI 的状态机包含了 4 个状态,也是名字的由来:
- (M)odified: 单副本 + 脏数据(即缓存改变,未写回内存)
- (E)xclusive: 单副本 + 干净数据
- (S)hared: 多副本 + 干净数据
- (I)nvalid: 数据未加载或缓存已失效
3.1. 工作原理
具体 CPU 如何从主内存中加载变量进行运行的过程,在 CPU 缓存架构中有详解,这里不做过多的解释
1.假设 CPU1 率先抢到时间片,当变量 count 加载至 CPU 缓存中时,会将 count 的使用标志为(E 独占:首次加载会将变量置为独占,也就说明没有其他 CPU 进行加载)
2.CPU2 也获得时间片,把变量 count 加载缓存中,此时 count 的使用标志为(E 独占),并发送消息至总线,告知其他 CPU 读取了变量的值,各 CPU 通过时刻监听(总线嗅探机制)获得到此变量已被多个 CPU 所加载,那么此时 CPU2 就会将自身 count 的使用标志置为(S 共享),CPU1 也会将变量的使用标志也会置为(S)
3.CPU1 从缓存中加载 count 至寄存器中进行自增操作,执行完毕之后,count = 0 -> 1,此时由于 count 的值发生了变化,因此 CPU1 中变量 count 使用标志应为(M 修改),此时 CPU1 会发送消息至总线,告知其他线程已经修改了变量 count 的值,其他 CPU 嗅探到值的修改,就会将自身变量 count 的使用标志置为(I 无效)
4.CPU1 会将 M 状态的变量立刻写回至主内存中,写回完毕之后,CPU1 会将使用状态置为(E 独享),发送消息至总线,告知其他 CPU 已经写回完毕,其他 CPU 会再此从主内存中读取变量 count 的值,读取完毕之后,也会发送消息至总线,其他 CPU 嗅探到之后将自身变量 count 置为(S 共享),自身变量的使用状态也会置为(S 共享)
MESI 失效时,缓存锁会退化到总线锁,失效的情况:
- 当缓存行存储的数据超过最小存储单元大小时(数据长度存储跨越多个缓存行的情况),就会导致 MESI 操作缓存行无效,导致 MESI 缓存一致性协议失效;
- 系统不支持缓存一致性协议。
缓存行大小:32B、64B、128B(因系统而定)
3.2. 状态变换
[[../../../../cubox/006-ChromeCapture/并发研究之CPU缓存一致性协议(MESI) - 枫飘雪落 - 博客园]]
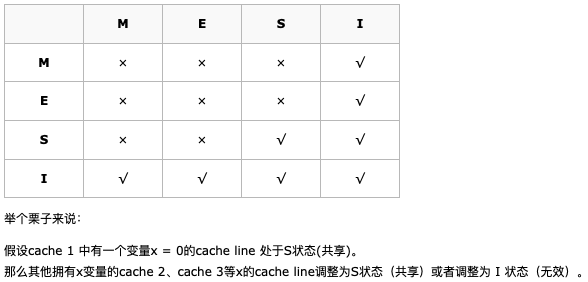
| 状态 | 描述 | 监听任务 |
|---|---|---|
| M 修改 (Modified) | 该 Cache line 有效,数据被修改了,和内存中的数据不一致,数据只存在于本 Cache 中。 | 缓存行必须时刻监听所有试图读该缓存行相对就主存的操作,这种操作必须在缓存将该缓存行写回主存并将状态变成 S(共享)状态之前被延迟执行。 |
| E 独享、互斥 (Exclusive) | 该 Cache line 有效,数据和内存中的数据一致,数据只存在于本 Cache 中。 | 缓存行也必须监听其它缓存读主存中该缓存行的操作,一旦有这种操作,该缓存行需要变成 S(共享)状态。 |
| S 共享 (Shared) | 该 Cache line 有效,数据和内存中的数据一致,数据存在于很多 Cache 中。 | 缓存行也必须监听其它缓存使该缓存行无效或者独享该缓存行的请求,并将该缓存行变成无效(Invalid)。 |
| I 无效 (Invalid) | 该 Cache line 无效。 | 无 |
在 MESI 协议中,每个 Cache 的 Cache 控制器不仅知道自己的读写操作,而且也监听 (snoop) 其它 Cache 的读写操作。每个 Cache line 所处的状态根据本核和其它核的读写操作在 4 个状态间进行迁移
Local Read 表示本内核读本 Cache 中的值,Local Write 表示本内核写本 Cache 中的值,Remote Read 表示其它内核读其它 Cache 中的值,Remote Write 表示其它内核写其它 Cache 中的值,箭头表示本 Cache line 状态的迁移,环形箭头表示状态不变。 当内核需要访问的数据不在本 Cache 中,而其它 Cache 有这份数据的备份时,本 Cache 既可以从内存中导入数据,也可以从其它 Cache 中导入数据,不同的处理器会有不同的选择。MESI 协议为了使自己更加通用,没有定义这些细节,只定义了状态之间的迁移,下面的描述假设本 Cache 从内存中导入数据.
[[../../../../cubox/006-ChromeCapture/并发原理系列一:MESI与内存屏障-今日头条]]
[[../../../../cubox/006-ChromeCapture/CPU高速缓存行与内存关系 及并发MESI 协议 - JokerJason - 博客园]]
[[../../../../cubox/006-ChromeCapture/聊聊缓存一致性协议 - Yungyu - 博客园]]
[[../../../../cubox/006-ChromeCapture/CPU缓存一致性协议—MESI详解 - 提拉没有米苏 - 博客园]]
3.3. 5 种协议消息
Mesi 协议消息
Read:”read” 消息用来获取指定物理地址上的 cache line 数据。
Read Response:该消息携带了 “read” 消息所请求的数据。read response 可能来自于 memory 或者是其他 CPU cache。
Invalidate:该消息将其他 CPU cache 中指定的数据设置为失效。该消息携带物理地址,其他 CPU cache 在收到该消息后,必须进行匹配,发现在自己的 cache line 中有该地址的数据,那么就将其从 cahe line 中移除,并响应 Invalidate Acknowledge 回应。Invalidate Acknowledge 消息用做回应 Invalidate 消息。
Read Invalidate:该消息中带有物理地址,用来说明想要读取哪一个 cache line 中的数据。这个消息还有 Invalidate 消息的效果。其实该消息是 read + Invalidate 消息的组合,发送该消息后 cache 期望收到一个 read response 消息。
Writeback: 该消息带有地址和数据,该消息用在 modified 状态的 cache line 被置换时发出,用来将最新的数据写回 memory 或其他下一级 cache 中。
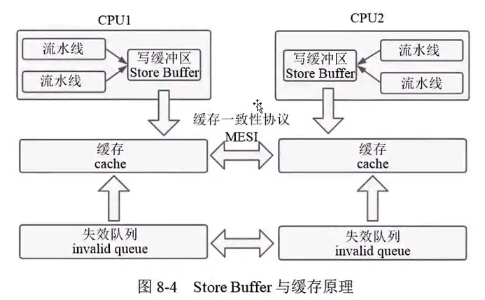
3.4. Store Buffer⭐️🔴
❕ ^pyabmn
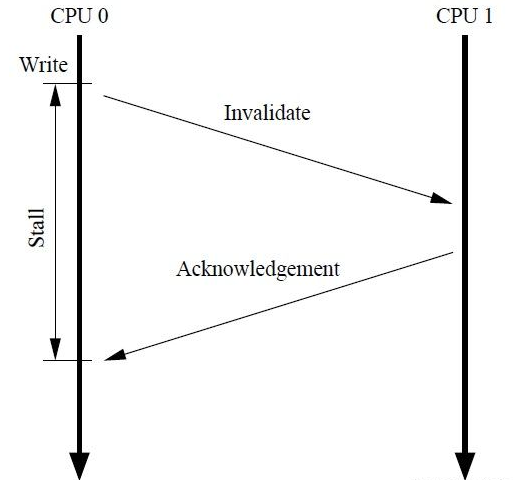
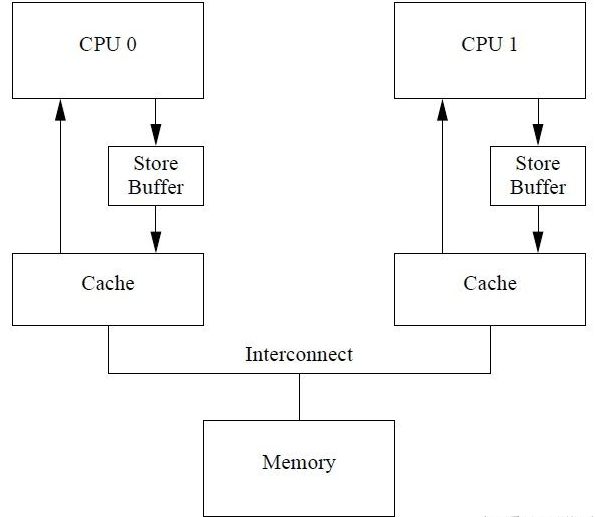
当 cpu0 要写数据到本地 cache的时候,如果不是 M 或者 E 状态,需要发送一个 invalidate 消息给 cpu1,只有收到 cpu1 的 acknowledgement 才能写数据到 cache 中,在这个过程中 cpu0 需要等待,这大大影响了性能。一种解决办法是在 cpu 和 cache 之间引入 store buffer,当发出 invalidate 之后直接把数据写入 store buffer。当收到 acknowledgement 之后可以把 store buffer 中的数据写入 cache。
现在的架构图是这样的: ^47f91q
Store Buffer 的确提高了 CPU 的资源利用率,不过优化了带来了新的问题。在新数据存储在 Store Buffer 里时,如果此时有一条 read 指令,若仍旧从 cache 中读取数据时,读到的是旧的数据。要解决这个问题就必须要求 CPU 读取数据时得先看 Store Buferes 里面有没有,如果有则直接读取 Store Buferes 里的值,如果没有才能读取自己缓存里面的数据,这也就是所谓的“Store Forward”。
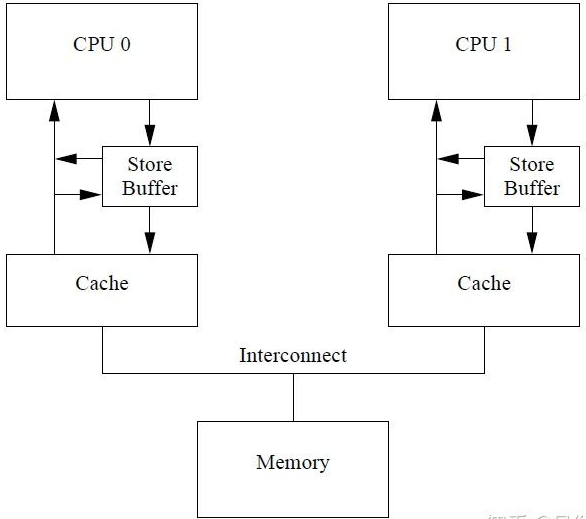
3.5. Invalidate Queue⭐️🔴
但是内存屏障的处理方法有个问题,那就是 store buffer 空间是有限的,如果 store buffer 中的空间被 smp_mb 之后的存储塞满,cpu 还是得等待 invalidate 消息返回才能继续处理。解决这种问题的思路是让 invalidate ack 能更早得返回,一种办法是提供一种放置 invalidate message 的队列,称为 invalidate queue. cpu 可以在收到 invalidate 之后马上返回 invalidate ack,而不是在把本地 cache invalidate 之后,并把 invalidate message 放置到 invalide queue,以待之后处理。
CPU 其实不需要完成 invalidate 操作就可以回送 acknowledge 消息,这样,就不会阻止发生 invalidate 请求的那个 CPU 进入无聊的等待状态。CPU 可以 buffer 这些 invalidate message(放入 Invalidate Queues),然后直接回应 acknowledge,表示自己已经收到请求,随后会慢慢处理。
3.6. 读写屏障⭐️🔴
store buffer 和 invalidate queue 的引入导致不满足全局有序,所以需要有写屏障和读屏障。
读屏障用于处理 invalidate queue,写屏障用于处理 store buffer。
X86 架构下的读屏障指令是 lfenc,写屏障指令是 sfence,读写屏障指令是 mfence。
3.6.1. 读屏障⭐️🔴
作用:所有读屏障之前发生的内存更新,对读屏障之后的 load 操作都是可见的
cpu 实际操作: 把 失效队列(invalidate queue)里的实效指令(I)全部执行
3.6.2. 写屏障⭐️🔴
作用:所有写屏障之前发生的内存更新(M)对之后的命令都是可见的
cpu 实际操作:等到 存储缓存(store buffer)为空(所有更新已刷出),cpu 才能执行写屏障之后指令
3.6.3. Full 屏障
作用:上述二者之和
cpu 实际操作:上述二者之后
3.7. cache 写策略
Write-through(直写模式)在数据更新时,同时写入缓存 Cache 和后端存储。此模式的优点是操作简单;缺点是因为数据修改需要同时写入存储,数据写入速度较慢。
Write-back(回写模式)在数据更新时只写入缓存 Cache。只在数据被替换出缓存时,被修改的缓存数据才会被写到后端存储。此模式的优点是数据写入速度快,因为不需要写存储;缺点是一旦更新后的数据未被写入存储时出现系统掉电的情况,数据将无法找回。
3.8. 总线嗅探
高速缓存有缓存控制器,然后用来监视总线,如果某一个 CPU 想要修改共享缓存的数据,它会先进行广播,其他的 CPU 就会嗅探到这个事务或者广播。然后他们会判断自己本地高速缓存是否也有这样的数据副本,如果没有则不用理会。
总线嗅探机制一般分为两种协议,一种是写失效协议 (write-invalidate),一个核心写入缓存后,会广播一个失效请求,其他核心嗅探到则将自己缓存中对应的缓存行标记为失效; 另一种是写更新协议 (write-update),写入缓存的核心除了要广播一个失效请求外,还要广播数据内容,把对应数据传输给其他 CPU。如果有则通常让他们无效 (write-invalidate) 或者更新 (write-update)。但是对于总线嗅探来说,一般都是使用 write-invalidate,让这些数据无效,因为 write-update 会产生数据拷贝,产生总线流量。
原文链接: https://blog.csdn.net/zhanglh046/article/details/115307993
3.9. 状态流转案例
MESI
MESI 通过给每一个 Cache Line 设置一个大小为 2bit (四个状态)的状态位来保证一致性
状态 描述
M(Modified) 被修改的,该 Cache Line 被当前 CPU 核心修改了,和主存不一致,但是是最新的数据,可以直接使用
E(Exclusive) 独占的,该 Cache Line 只有当前 CPU 核心有,而且数据和主存一样,可以直接使用
S(Shared) 共享的,有多个 CPU 核心里有该 Cache Line,而且数据和主存一样,可以直接使用
I(Invalid) 失效的,表示该 Cache Line 无效,需要读取数据就直接取主存中读取即可
例子
情景:假设现在存在一个 CPU 存在两个核心 core a, core b;
3.9.1. 读取数据
core a 需要读取数据 x
core a 会先查看自己的缓存中是否有该数据:
如果存在,就查看 Cache Line 的状态,如果是 M,E,S 的话直接使用即可
如果不存在,或者 状态是 I ,就会向总线发起读请求 (read),其他 CPU 核心就会监听该消息,并检查自己有没有该数据:
- 如果 core b 缓存中没有该数据,core a 就直接到主存中读取数据即可
- 如果 core b 缓存中有该数据, 状态是 E ,说明 core b 的缓存和主存一致,那么 core b 就会把该 数据发送到总线,让 core a 去获取数据,还需要把状态改为 S
- 如果 core b 缓存中有该数据,状态是 S ,说明 core b 的缓存和主存一致,那么 core b 就会把该 数据发送到总线,让 core a 去获取数据
- 如果 core b 缓存中有该数据,状态是 M,说明 core b 的缓存和主存不一致,那么 core b 需要先把数据写到主存中,把状态改为 S,分享给 core a
- 如果 core b 缓存中有该数据,状态是 I,core a 就直接到主存中读取数据即可
3.9.2. 写入数据
core a 需要写入数据 x
core a 会先查看自己的缓存中是否有该数据:
如果存在,并且 Cache Line 的状态为 M ,说明该数据只有在 core a 中是最新的,那么直接修改数据即可,状态不变
如果存在,并且 Cache Line 的状态为 E ,说明该数据只有在 core a 中是最新的,那么直接修改数据,然后修改状态为 M
如果存在,并且 Cache Line 的状态为 S ,说明该数据在其他核心中存在备份,那么需要发出一个 RFO (Request For Owner) 请求,它需要拥有这行数据的权限,通知到其他的 CPU 核心, 自己对该数据进行了修改, 其他核心需要把自己对应的 Cache Line 的状态改为 I ,即无效,core a 需要修改状态为 M
如果不存在或者为 Cache Line 状态为 I ,就需要先读取数据到缓存中(回到上面的读取数据流程),然后修改状态为 M ,同时发消息到总线通知其他核心将该数据状态改为 I
[[../../../../cubox/006-ChromeCapture/看懂这篇,才能说了解并发底层技术 - 腾讯云开发者社区-腾讯云]]
初始 I 状态:一开始时,缓存行没有加载任何数据,所以它处于 I 状态。
本地写(Local Write):如果本地处理器写数据至处于 I 状态的缓存行,则缓存行的状态变成 M。
本地读(Local Read):如果本地处理器读取处于 I 状态的缓存行,很明显此缓存没有数据给它。此时分两种情况:
- (1) 其它处理器的缓存里也没有此行数据,则从内存加载数据到此缓存行后,再将它设成 E 状态,表示只有我一家有这条数据,其它处理器都没有;
- (2) 其它处理器的缓存有此行数据,则将此缓存行的状态设为 S 状态。(备注:如果处于 M 状态的缓存行,再由本地处理器写入/读出,状态是不会改变的)
远程读(Remote Read):假设我们有两个处理器 c1 和 c2,如果 c2 需要读另外一个处理器 c1 的缓存行内容 (由 c1 应答 c2 的 read 请求),c1 需要把它缓存行的内容通过内存控制器 (Memory Controller) 发送给 c2,c2 接到后将相应的缓存行状态设为 S。在设置之前,内存也得从总线上得到这份数据并保存。
远程写(Remote Write):其实确切地说不是远程写,而是 c2 得到 c1 的数据后,不是为了读,而是为了写。也算是本地写,只是 c1 也拥有这份数据的拷贝,这该怎么办呢?c2 将发出一个 RFO (Request For Owner) 请求,它需要拥有这行数据的权限,其它处理器的相应缓存行设为 I,除了它自已,谁不能动这行数据。这保证了数据的安全,同时处理 RFO 请求以及设置 I 的过程将给写操作带来很大的性能消耗。
3.10. 落地实现
AMD 的 Opteron 处理器使用从 MESI 中演化出的MOESI 协议,O(Owned) 是 MESI 中 S 和 M 的一个合体,表示本 Cache line 被修改,和内存中的数据不一致,不过其它的核可以有这份数据的拷贝,状态为 S。
Intel 的 core i7 处理器使用从 MESI 中演化出的MESIF 协议,F(Forward) 从 Share 中演化而来,一个 Cache line 如果是 Forward 状态,它可以把数据直接传给其它内核的 Cache,而 Share 则不能。
https://www.cnblogs.com/cherish010/p/8602635.html
4. 屏障和 Lock
并发编程专题-基础-10、内存屏障5. 总结 - 来龙去脉⭐️🔴⭐️🔴
- 因为内存的速度和 CPU 匹配不上,所以在内存和 CPU 之间加了多级缓存。
- 单核 CPU 独享不会出现数据不一致的问题,但是多核情况下会有缓存一致性问题。
- 缓存一致性协议就是为了解决多组缓存导致的缓存一致性问题。
- 缓存一致性协议有两种实现方式,一个是基于目录的,一个是基于总线嗅探的。
- 基于目录的方式延迟高,但是占用总线流量小,适合 CPU 核数多的系统。
- 基于总线嗅探的方式延迟低,但是占用总线流量大,适合 CPU 核数小的系统。
- 常见的 MESI 协议就是基于总线嗅探实现的。
- MESI 解决了缓存一致性问题,但是还是不能将 CPU 性能压榨到极致。
!并发基础-1、JMM与MESI - 为了进一步压榨 CPU,所以引入了 store buffer 和 invalidate queue。
- store buffer 和 invalidate queue 的引入导致不满足全局有序,所以需要有写屏障和读屏障。
- X86 架构下的读屏障指令是 lfenc,写屏障指令是 sfence,读写屏障指令是 mfence。
- lock 前缀指令直接锁缓存行,也能达到内存屏障的效果。
- x86 架构下,volatile 的底层实现就是 lock 前缀指令。
- JMM 是一个模型,是一个便于 Java 开发人员开发的抽象模型。
- 缓存性一致性协议是为了解决 CPU 多核系统下的数据一致性问题,是一个客观存在的东西,不需要去触发。
- JMM 和缓存一致性协议没有一毛钱关系。
- JMM 和 MESI 没有一毛钱关系。
6. 参考与感谢
[[关于缓存一致性协议、MESI、StoreBuffer、InvalidateQueue、内存屏障、Lock指令和JMM的那点事 HeapDump性能社区]]
[[MESI 协议学习笔记 三点水]]
[[内存屏障及其在 JVM 下的应用 — Blogs by ylgrgyq]]
👍 [[cpu缓存和volatile - XuMinzhe - 博客园]]
JMM 完善于 JSR-133,现在一般会把详细说明放在 Java Language 的 Spec 上,比如 Java11 的话在:Chapter 17. Threads and Locks。在这些说明之外,还有个特别出名的 Cookbook,叫 The JSR-133 Cookbook for Compiler Writers
 微信
微信 支付宝
支付宝