
Java基础-集合框架-9、集合面试题
1. ConcurrentHashMap 的 size() 方法是线 程安全的吗?为什么
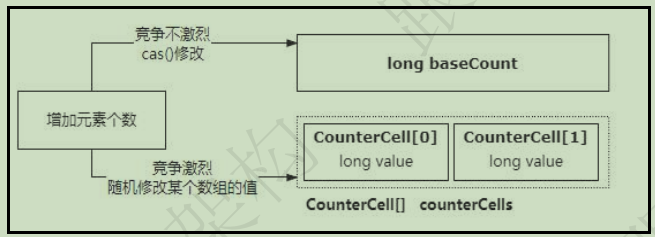
ConcurrentHashMap 的 size() 方法是非线程安全的。也就是说,当有线程调用 put 方法在添加元素的时候,其他线程在调用 size() 方法获取的元素个数和实际存储元素个数是不一致的。
原因是 size() 方法是一个==非同步方法==,put() 方法和 size() 方法并没有实现同步锁put() 方法的实现逻辑是:在 hash 表上添加或者修改某个元素,然后再对总的元素个数进行累加。其中,线程的安全性仅仅局限在 hash 表数组粒度的锁同步,避免同一个节点出现数据竞争带来线程安全问题。
数组元素个数的累加方式用到了两个方案:
- 当线程竞争不激烈的时候,直接用 cas 的方式对一个 long 类型的变量做原子递增。
- 当线程竞争比较激烈的时候,使用一个 CounterCell 数组,用分而治之的思想减少多线程竞争,从而实现元素个数的原子累加。
size() 方法的逻辑就是遍历 CounterCell 数组中的每个 value 值进行累加,再加上 baseCount,汇总得到一个结果。所以很明显,size() 方法得到的数据和真实数据必然是不一致的。因此从 size() 方法本身来看,它的整个计算过程是线程安全的,因为这里用到了 CAS 的方式解决了并发更新问题。但是站在 ConcurrentHashMap 全局角度来看,put() 方法和 size() 方法之间的数据是不一致的,因此也就不是线程安全的。
之所以不像 HashTable 那样,直接在方法级别加同步锁。在我看来有两个考虑点。直接在 size() 方法加锁,就会造成数据写入的并发冲突,对性能造成影响,当然 有些朋友会说可以加读写锁,但是同样会造成 put 方法锁的范围扩大,性能影响极大! ConcurrentHashMap 并发集合中,对于 size() 数量的一致性需求并不大,并发 集合更多的是去保证数据存储的安全性。
2. HashMap 中的 hash 方法为什么要右移 16 位异或?
之所以要对 hashCode 无符号右移 16 位并且异或,核心目的是为了让 hash 值的散列度更高,尽可能减少 hash 表的 hash 冲突,从而提升数据查找的性能。
在 HashMap 的 put 方法里面,是通过 Key 的 hash 值与数组的长度取模计算得 到数组的位置。 而在绝大部分的情况下,n 的值一般都会小于 2^16 次方,也就是 65536。 所以也就意味着 i 的值 , 始终是使用 hash 值的低 16 位与 (n-1) 进行取模运算, 这个是由与运算符&的特性决定的。 这样就会造成 key 的散列度不高,导致大量的 key 集中存储在固定的几个数组位置,很显然会影响到数据查找性能。因此,为了提升 key 的 hash 值的散列度,在 hash 方法里面,做了位移运算。 首先使用 key 的 hashCode 无符号右移 16 位,意味着把 hashCode 的高位移动到了低位。 然后再用 hashCode 与右移之后的值进行异或运算,就相当于把高位和低位的特征进行组合。 从而降低了 hash 冲突的概率。
2.1. 二次哈希
二次哈希指的是将哈希码的高 16 位与低 16 位进行异或运算得到的加工过的哈希码
3. HashMap 死循环
4. ConcurrentHashMap 是如何保证线程安全的
5. 参考与感谢
集合框架-7、ConcurrentHashMap(JDK1.8) 面试专题-7、八股文 微信
微信 支付宝
支付宝
