
Java基础-集合框架-7、ConcurrentHashMap(JDK1.8)
1. 容器初始化
https://www.bilibili.com/video/BV17i4y1x71z?t=421.7
1.1. 源码分析
在 jdk8 的 ConcurrentHashMap 中一共有 5 个构造方法,这四个构造方法中都没有对内部的数组做初始化, 只是对一些变量的初始值做了处理
jdk8 的 ConcurrentHashMap 的数组初始化是在第一次添加元素时完成
PS: 传入 32,最终大小为 64,与前面的都不同
注意,调用这个方法,得到的初始容量和我们之前讲的 HashMap 以及 jdk7 的 ConcurrentHashMap 不同,即使你传递的是一个 2 的幂次方数,该方法计算出来的初始容量依然是比这个值大一点的 2 的幂次方数
JDK1.8: 传递进来一个初始容量,ConcurrentHashMap 会基于这个值计算一个比这个值大一半的 2 的幂次方数作为初始容量
1 | |
1 | |
1.2. sizeCtl 含义解释
注意:以上这些构造方法中,都涉及到一个变量
sizeCtl,这个变量是一个非常重要的变量,而且具有非常丰富的含义,它的值不同,对应的含义也不一样,这里我们先对这个变量不同的值的含义做一下说明,后续源码分析过程中,进一步解释
sizeCtl为 0,代表数组未初始化, 且数组的初始容量为 16
sizeCtl为正数,如果数组未初始化,那么其记录的是数组的初始容量,如果数组已经初始化,那么其记录的是数组的扩容阈值
sizeCtl为 -1,表示数组正在进行初始化
sizeCtl小于 0,并且不是 -1,表示数组正在扩容, -(1+n),表示此时有 n 个线程正在共同完成数组的扩容操作
2. 添加安全
2.1. 总体概述⭐️🔴

- 如果 tab 为空,调用 initTable() 方法进行初始化,通过
CAS+自旋保证线程安全 - 如果 tab 不为空,就判断所在的桶是否为空,如果是的话,说明是第一个元素,就调用
casTabAt()方法直接新建节点添加到 Node 数组中就可以了 - 如果正在扩容,就帮助扩容
- 如果没有扩容也不为空,就把元素插入桶中,先使用 synchronized 进行加锁,这个锁的粒度就是数组的具体的一个元素,fh 是当前索引位置的 hash 值,如果大于等于 0,说明是链表,否则是红黑树。链表插入会对 binCount 加一操作,新元素插入尾部,如果 key 相同覆盖原来的值
- 判断 binCount 是否大于等于 TREEIFY_THRESHOLD(值为 8) ,这时候调用 treeifyBin() 方法考虑将链表转换为红黑树,真正要转为红黑树还要求数组长度大于 64
2.2. 数组初始化,initTable 方法
1 | |
2.2.1. 流程图
https://www.processon.com/view/link/6369aced0e3e74618c3a6872
2.3. 添加元素 put/putVal 方法
1 | |
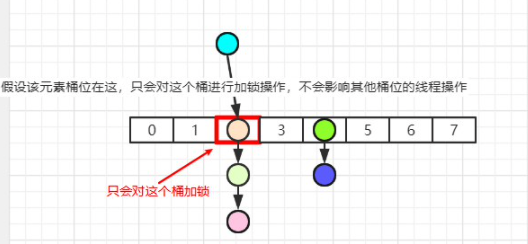
通过以上源码,我们可以看到,当需要添加元素时,会针对当前元素所对应的桶位进行加锁操作,这样一方面保证元素添加时,多线程的安全,同时对某个桶位加锁不会影响其他桶位的操作,进一步提升多线程的并发效率
2.3.1. 图示
2.3.2. 流程图
https://www.processon.com/view/link/636a35ec5653bb5ba36c0559
3. 扩容安全
3.1. 源码分析
1 | |
3.2. 疑问
3.2.1. fh>=0⭐️🔴
❕ ^chx2qw
因为在 spread(key.hashCode()) 方法中 (h ^ (h >>> 16)) & HASH_BITS 保证了 hash 为非负数
然后 TreeBin 中的 static final int TREEBIN = -2,所以可以如此判断链表还是红黑树
3.3. 图解
图示为方便画图为 4,实际源码中为 16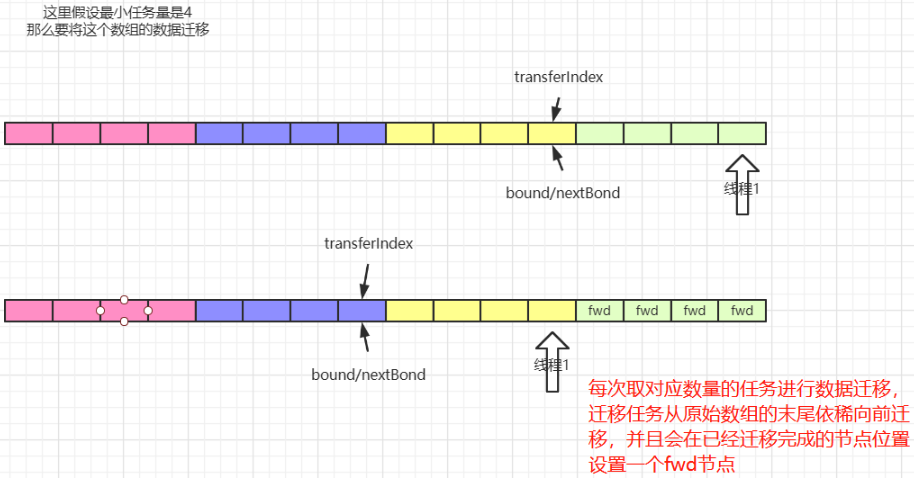
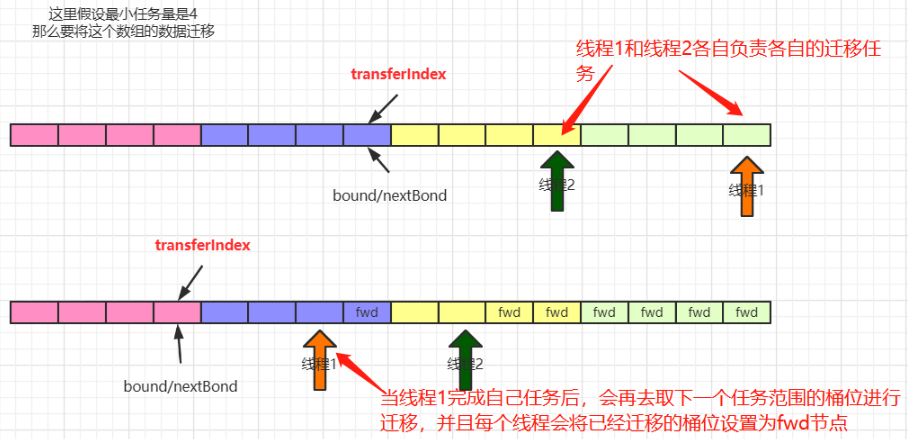
4. 多线程扩容
多线程协助扩容的操作会在两个地方被触发:
① 当添加元素时,发现添加的元素对用的桶位为 fwd 节点,就会先去协助扩容,然后再添加元素
② 当添加完元素后,判断当前元素个数达到了扩容阈值,此时发现 sizeCtl 的值小于 0,并且新数组不为空,这个时候,会去协助扩容
4.1. 源码分析
4.1.1. 元素未添加时协助扩容
元素未添加,先协助扩容,扩容完后再添加元素
1 | |
1 | |
1 | |
4.1.2. 先添加元素再协助扩容
1 | |
4.2. 图解
5. 集合长度的累计方式
5.1. addCount 方法
5.1.1. 作用
两个作用 : 添加 (统计) 容器元素个数 、 检查是否达到了阈值而执行扩容操作.
5.1.2. 主要逻辑
① CounterCell 数组不为空,优先利用数组中的 CounterCell 记录数量
② 如果数组为空,尝试对 baseCount 进行累加,失败后,会执行 fullAddCount 逻辑
③ 如果是添加元素操作,会继续判断是否需要扩容
5.1.3. 源码
1 | |
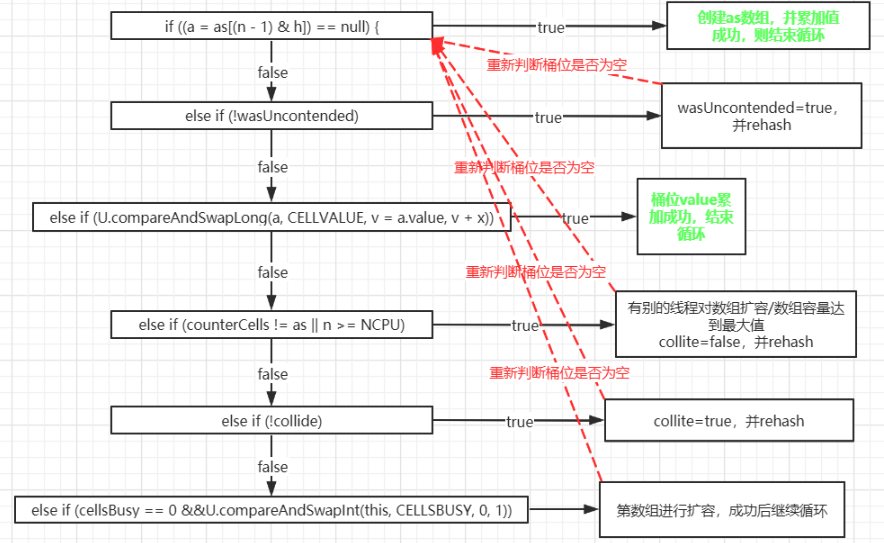
5.2. fullAddCount 方法
① 当 CounterCell 数组不为空,优先对 CounterCell 数组中的 CounterCell 的 value 累加
② 当 CounterCell 数组为空,会去创建 CounterCell 数组,默认长度为 2,并对数组中的 CounterCell 的 value 累加
③ 当数组为空,并且此时有别的线程正在创建数组,那么尝试对 baseCount 做累加,成功即返回,否则自旋
1 | |
5.3. 图解
6. 集合长度获取
1 | |
7. 参考
7.1. 黑马
❕ ^5h9x2g
7.1.1. 视频
7.1.2. 资料
1 | |
[[ConcurrentHashMap源码分析(二)]]
[[20221108-ConcurrentHashMap - 知乎]]
 微信
微信 支付宝
支付宝
